https://www.lgresearch.ai/blog/view?seq=401
[WACV 2024] 비전검사 분야의 산업용 이상 탐지 기술과 활용 - LG AI Research BLOG
WACV 2024, 비전검사, 이상 탐지 기술
www.lgresearch.ai
[WACV 2024] 비전검사 분야의 산업용 이상 탐지 기술과 활용
1. Introduction
‘이상 탐지(Anomaly Detection)’란 어떤 데이터 집합에서 예상할 수 있는 기대 관측 값이 아닌 다른 형태의 데이터 패턴을 찾아내는 것을 목표로 하는 분야를 의미합니다. 사람은 변화가 발생하면 일반적으로 발생된 정상의 데이터 패턴인지 아니면 비정상적으로 형성된 패턴인지를 구분할 수 있는 능력을 가지고 있습니다. 이는 정상적인 데이터 패턴의 양상을 학습을 통해 기억하고 있기 때문입니다. 딥러닝(Deep Learning)을 이용한 이상 탐지 기술들은 이와 유사하게 데이터의 일반적인 패턴 분포를 학습하여 기억하고 있다가 이를 벗어난 패턴을 검출하는 방식으로 이상 징후를 탐지합니다.
이러한 이상 탐지 기술은 네트워크에서 발생되는 이상 징후를 탐지하거나 고객의 소비 패턴과 다른 징후를 찾아내어 신용카드 복제 및 도난 사용을 예측하기 위해 사용하는 등 보안 및 금융 분야 등에서도 널리 활용되고 있습니다.
그림 1. 반복되는 일반적인 정상 패턴에서 벗어난 이상 징후 예시 이미지
2. 비전검사 분야의 산업용 이상 탐지(Industrial Anomaly Detection) 기술
제조 산업에서 결함이 있는 제품을 찾아내는 것은 품질 관리를 위해 매우 중요한 요소입니다. 비전검사는 제품 외관에 발생된 결함을 찾아내는 것이 목적이며, 룰 기반 알고리즘의 성능을 보완하기 위해 딥러닝 기반의 알고리즘을 활용하는 사례들이 늘고 있습니다.
회사는 생산성을 극대화하고자 대규모 제품을 결함 없이 생산하기 위해 생산 공정 라인에 많은 노력을 기울이고 있습니다. 따라서 일반적으로 극소수의 결함 데이터만이 발생이 되며, 이는 ‘클래스 불균형(Class Imbalance)’ 문제의 원인이 됩니다. 이러한 클래스 불균형 문제는 제품 결함을 검출하기 위한 분류 모델이 편향된 결과를 나타내도록 만드는 요인입니다. 또한 분류 모델은 학습 시점에서의 유형 이외의 신규 유형의 이미지 데이터가 발생한 경우에 잘못된 예측을 내릴 가능성이 높습니다.
정상 제품의 일반적인 특징 분포를 학습하여 기억하고 있다가 이를 벗어난 특징을 검출하는 방식인 이상 탐지 모델(Anomaly Detection Models)로 위와 같은 문제들을 해결할 수 있습니다. 제품 이미지에서 이상을 감지하는 방법은 하기 그림 2과 같이 3가지 형태로 범주화해 볼 수 있습니다. 밀도(Density)와 거리(Distance) 기반 방법을 임베딩(Embedding) 기반 방법으로 묶어서 2가지 형태로 범주화하는 시각도 있으나, 여기서는 3가지 형태로 범주화하여 살펴보도록 하겠습니다.
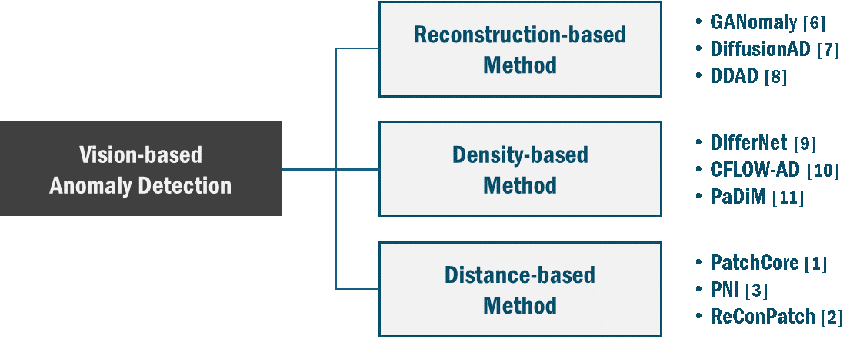
그림 2. 제품 이미지에서 이상을 감지하는 3가지 형태
첫 번째 복원(Reconstruction)을 기반으로 하는 방법들은 정상 제품 이미지의 특징 구조를 잘 표현할 수 있는 축소된 차원(Dimension)을 학습하여 구성하고, 축소 차원으로부터 이미지를 복원하는 과정 중에 나타나는 복원 오류(Error)의 편차를 이용하여 이상을 탐지합니다. 정상 제품에 비해 이상 제품 이미지는 높은 복원 오류를 보입니다. 자동부호기(Autoencoder)나 생성적 적대 신경망(Generative Adversarial Network)을 이용하는 방법들이 제안되어 왔으나, 최근에는 생성 모델로 각광받고 있는 확산 모델(Diffusion Model)을 이용한 방법들이 발표되고 있습니다.
두 번째로 밀도(Density) 기반의 방법은 제품의 이상 데이터는 낮은 밀도에 위치할 가능성이 높다는 특성을 이용합니다. 정상 제품 이미지로부터 확률 밀도 함수를 모델링하고 주어진 입력 데이터의 확률 밀도를 측정하여 이상을 탐지하는 방법을 말합니다. 가우스 혼합 모델(Gaussian Mixture Model), 흐름 정규화(Normalizing Flow) 등을 기반으로 하는 이상 탐지 알고리즘들이 이러한 범주에 속한다고 볼 수 있습니다.
마지막으로 거리(distance) 기반 방법은 주어진 정상 제품 이미지의 대표적인 특징으로부터 얼마나 멀리 떨어져 있는가를 수치적으로 측정하여 이상을 탐지하는 방법을 말합니다. CVPR 2022에서 발표된 PatchCore가 대표적인 거리 기반 방법이고, 21년 5월부터 23년 초까지 MVTecAD 데이터셋 리더보드에서 SOTA 성능을 달성하고 있었습니다.
산업 환경에의 생산성과 효율성을 높이기 위한 다양한 AI 기술 연구 및 활용이 진행되고 있습니다. LG AI연구원의 Vision 랩에서도 제품 생산의 품질 관리 측면에서 비전 검사 AI 연구를 수행하고 있습니다. 이번 포스팅에서는 이상 탐지(Industrial Anomaly Detection)의 대표적인 알고리즘 중에 하나인 PatchCore에 대해서 알아보고, LG AI연구원이 컴퓨터 비전 분야 대표 학회 WACV 2024에서 발표한 ReConPatch를 소개해 보고자 합니다.
3. PatchCore
PatchCore는 이미지넷(ImageNet) 데이터 분류를 위해 학습된 모델을 사용하여 패치 단위의 특징을 추출하고, 코어셋 샘플링(Coreset Sampling) 과정을 통해 정상 제품 이미지의 대표 특징들을 선택하여 메모리 뱅크(Memory Bank)에 저장하는 학습 처리 과정을 수행합니다.
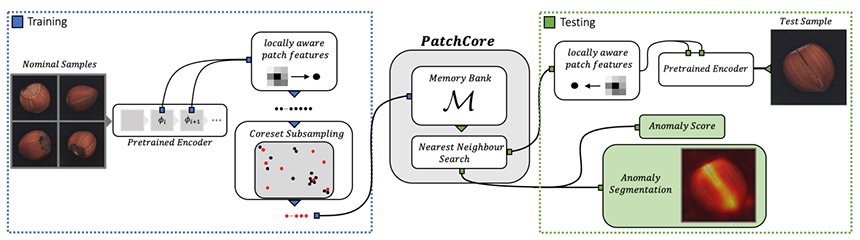
그림 3. PatchCore 개요도[1]
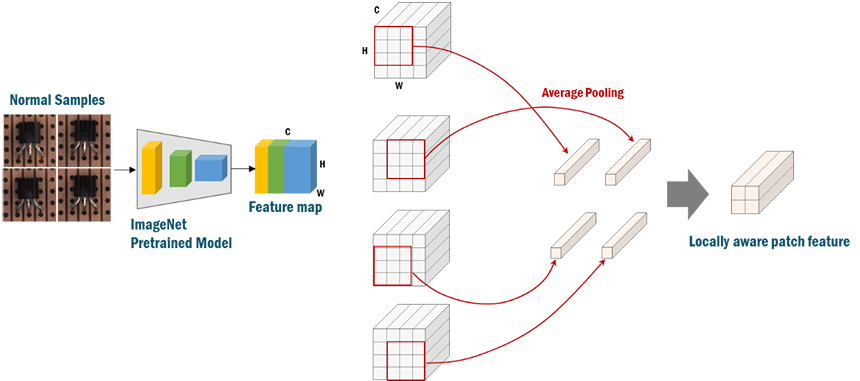
그림 4. 패치 특징 추출 과정
패치 특징 추출 과정에서는 먼저 이미지넷 사전 학습 모델의 각 합성곱 신경망(Convolutional Neural Network)의 결과를 결합하여 특징 지도(Feature Map)을 만듭니다. 각 합성곱 신경망의 해상도(Resolution)가 서로 다른 부분은 보간법(Interpolation)을 통한 크기 조정을 통해 동일한 해상도를 가지도록 맞춰줍니다. 특징 지도로부터 p 크기만큼의 영역을 평균 풀링(Average Pooling)을 통해 하나의 패치 특징을 추출하여 사용하는데, 그림 4에서는 p가 3인 경우의 예시를 보여주고 있습니다.
하나의 정상 제품 이미지에서도 다수의 패치 특징이 추출되고, 다수의 정상 제품 이미지를 학습에 사용하기 때문에 많은 양의 패치 특징들이 생성됩니다. 그래서 모든 패치 특징을 메모리 뱅크에 저장해야 할 경우에는 물리적인 메모리의 크기도 증대되어야 하고 특징 비교 횟수도 증가되기 때문에 추론 시간도 길어지는 문제가 발생합니다. 이를 해결하기 위해서는 패치 특징을 선택하여 저장해야 하는데 랜덤 샘플링의 경우에는 중복된 패치 특징이 선택될 가능성도 있고 특징 분포를 보존하지 못할 가능성도 높기 때문에 코어셋 샘플링을 통해 패치 특징을 선별합니다.
코어셋 샘플링의 과정은 아래 그림 5와 같습니다. 초기 코어셋을 랜덤하게 선정한 이후에는 최종적으로 n개의 코어셋을 얻을 때까지 (c)~(d)의 과정을 반복 수행합니다. 코어셋 샘플링을 통해 전체 특징 분포의 다양성을 보존하는 대표 특징들이 선정되며, 학습이 완료되면 정상 제품을 대표하는 n개의 패치 특징이 메모리 뱅크에 저장됩니다.
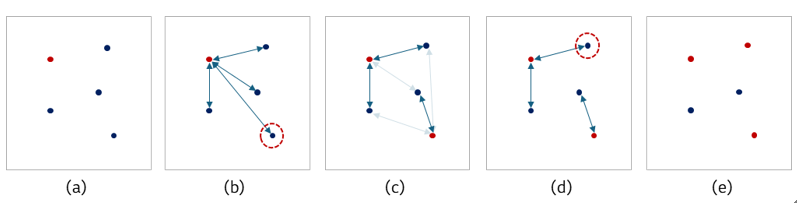
그림 5. 코어셋 샘플링 과정 예시 (a) 랜덤하게 1개의 특징을 초기 코어셋으로 선택,
(b) 각 특징으로부터 코어셋과의 거리를 측정하여 가장 멀리 떨어진 특징을 코어셋으로 선택
(c) 각 특징으로부터 코어셋과의 거리를 측정하여 각 특징마다 근접한 코어셋과의 거리를 선택
(d) 선택된 거리들 중에 가장 긴 거리를 가진 특징을 코어셋으로 선정 (e) 3개의 코어셋을 선정한 결과
입력 이미지가 주어졌을 때 메모리 뱅크에 저장된 정상 제품의 대표 특징과의 비교를 통해 입력 이미지가 정상 제품인지를 추론합니다. 위에 기술된 특징 추출 과정과 동일하게 입력 이미지로부터 패치 특징을 얻고, 최근접 이웃 탐색(Nearest Neighbor Search) 과정을 통해 메모리 뱅크 안에 저장된 특징 중 가장 근접한 특징을 찾아 거리를 측정합니다. 측정된 거리 중 최댓값을 찾아서 이를 이상 점수(Anomaly Score)로 사용하고, 이상 점수가 미리 정의한 임계치보다 높을 경우에 이상 제품으로 판정합니다.
4. ReConPatch
PatchCore는 산업 현장에서의 데이터가 아닌 일반적인 데이터로 구성된 이미지넷 데이터셋으로 학습한 모델을 사용하기 때문에 그림 6과 같이 동일한 위치에서 추출한 특징들의 분포가 분산되는 것을 볼 수 있습니다. 특징 분포가 넓다는 것은 정상 제품 이미지들 간에 편차가 크다는 것을 의미하기 때문에 입력 이미지가 주어졌을 때 정상 제품 이미지임에도 불구하고 높은 이상 점수로 측정될 수 있는 가능성이 있습니다. 이와 같은 문제점을 해결하기 위해 ReConPatch[2]에서는 유사한 패치 특징들의 분산은 줄여주고, 서로 다른 특징은 더욱 차이가 크게 발생될 수 있도록 학습을 합니다. 이를 통해 하기 그림과 같이 이상 제품 검출에 보다 적합한 특징들을 추출할 수 있습니다.
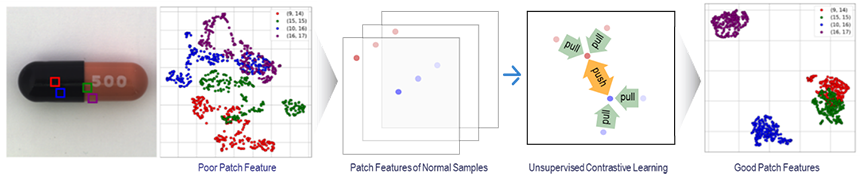
그림 6. 패치 특징 학습을 통한 임베딩(Embedding) 공간에서의 특징 분포 변환[2]
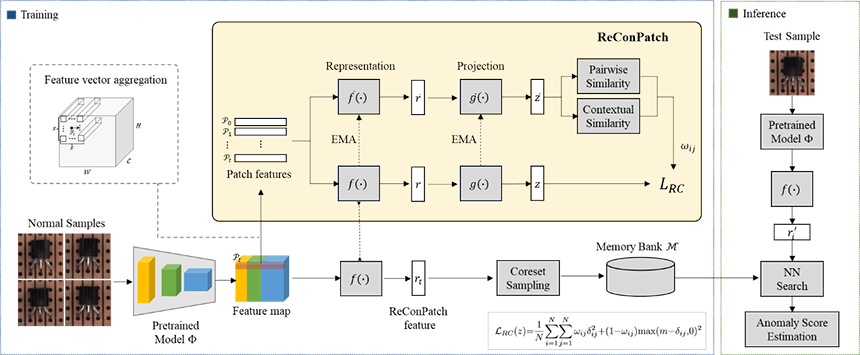
그림 7. ReConPatch 개요도[2]
그림 7에서 보는 바와 같이 ReConPatch는 패치 특징 간 쌍별 유사도(Pairwise Similarity)와 상황관계 유사도(Contextual Similarity)를 측정하여 유사도가 높을 경우에는 패치 특징이 더욱 근접해지도록 하고, 유사도가 낮을 경우에는 패치 특징이 미리 정의한 거리(
) 이상 멀어지도록 학습합니다. 그림 8과 같이 쌍별 유사도가 동일하다고 하더라도 (a)의 경우와 같이 멀어져야 할 수도 있고 (b)와 같이 하나의 군집군 안에 포함되어 있어서 근접해져야 할 수도 있습니다. 그래서 가장 근접한 k개의 특징 샘플을 추출하고 얼마나 많은 샘플들이 교집합을 이루고 있는지 측정하는 상황관계 유사도를 측정하여 쌍별 유사도와 함께 사용함으로써 보다 좋은 특징을 얻을 수 있도록 학습합니다.
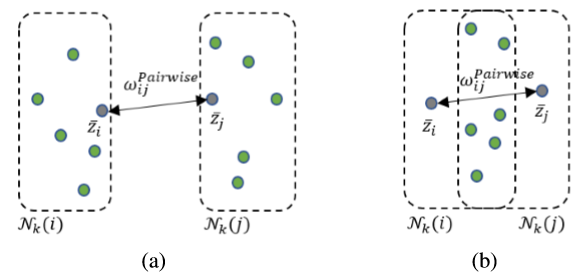
그림 8. 패치 특징의 유사도 측정 예시[2]
ReConPatch의 결과는 실제 이상이 발생한 영역에 비해 보다 넓게 예측된다는 것을 발견하였고, 이상 점수 지도(Anomaly Score Map)를 조정하는 후처리 과정을 통해 보다 정밀한 결과를 얻을 수 있습니다. Pni: industrial anomaly detection using position and neighborhood information[3]에서 제안한 방식과 유사하게 정상 제품 이미지에 인위적으로 이상 영역을 생성하여 합성한 이미지를 ReConPatch를 통해 이상 점수 지도를 예측하고 이를 재조정하는 RefinementNet을 학습합니다. 인위적으로 이상 영역을 생성한 주어진 정답 이미지에 가까워질 수 있도록 손실을 측정하는 방식으로 학습할 수 있으며, 그 결과 하기 그림 9과 같이 정밀한 결과를 얻을 수 있습니다.

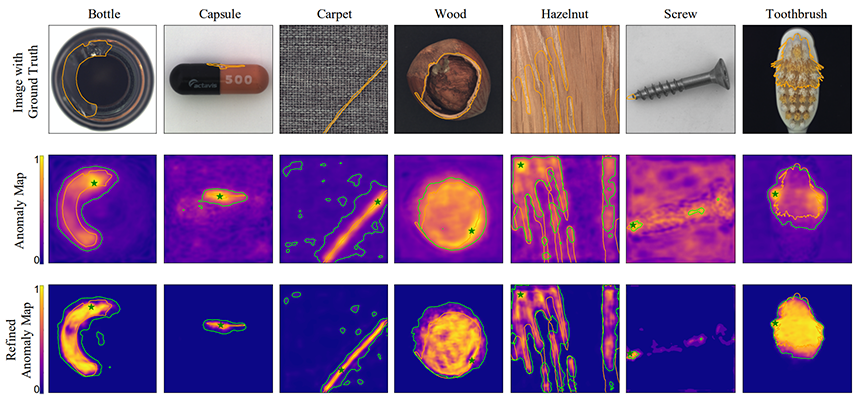
그림 9. 이상 점수 지도의 후처리 과정과 그 결과[2]
LG AI연구원이 WACV 2024에서 발표한 ReConPatch는 MVTecAD 데이터셋 리더보드[4, 5]에서 하기 테이블 1과 같이 SOTA 성능을 보여주고 있습니다. 특히, 정상과 이상 제품을 분류(Classification)하는 작업에 조금 더 특화된 성능을 보여주고 있습니다.
| Method | Image AUROC (Classification) |
Pixel AUROC (Segmentation) |
| ReConPatch Ensemble (w/ refinement) | 99.86 (1st) | 99.20 (2nd) |
| ReConPatch Ensemble | 99.72 (4th) | 98.67 (15th) |
테이블 1. MVTecAD 데이터셋에서의 ReConPatch 성능[2]
5. Conclusion
지금까지 비전검사 분야의 산업용 이상 탐지 기술 및 WACV 2024에서 발표한 LG AI연구원의 이상 감지 기술의 성과를 담은 논문에 대해서 살펴보았습니다. 딥러닝 기술과 함께 이상 탐지 기술은 매우 발전되어 왔으나, 생산 과정에서의 환경 변화로 인해 정상 제품에 대한 변화가 클 경우, 정상 제품에 대한 특징 분포가 넓게 분산되면서 성능이 저하되는 문제는 여전히 남아 있습니다. 하지만 제조 환경 특성상, 결함이 발생한 이상 제품 데이터를 수집하기가 매우 어렵기 때문에 이상 탐지 기술은 활용성이 매우 높으며, 딥러닝 기술 발전과 함께 더욱 성능이 향상될 가능성이 높은 분야라고 할 수 있습니다. LG AI연구원의 Vision 랩에서도 제조 환경에서의 한계들을 극복하고, 외관에서 발생된 결함을 효율적으로 검사할 수 있는 비전검사 AI 기술들을 더욱더 고도화하여 산업 환경에서의 AI 활용을 확장할 수 있을 것으로 기대하고 있습니다.
▶ReConPatch : Contrastive Patch Representation Learning for Industrial Anomaly Detection (Link)
[1] K.Roth et al, “Towards Total Recall in Industrial Anomaly Detection,” CVPR 2022
[2] Jeeho Hyun et al, “ReConPatch : Contrastive Patch Representation Learning for Industrial Anomaly Detection,” WACV 2024
[3] Jaehyeok Bae et al, “Pni: industrial anomaly detection using position and neighborhood information.” pages 6373?6383, 2023.
[4] https://www.mvtec.com/company/research/datasets/mvtec-ad
[5] https://paperswithcode.com/sota/anomaly-detection-on-mvtec-ad
[6] Samet Akcay et al, “GANomaly: Semi-Supervised Anomaly Detection via Adversarial Training,” ACCV 2018
[7] Hui Zhang et al, “DiffusionAD: Norm-guided One-step Denoising Diffusion for Anomaly Detection,” arxiv 2023.
[8] Arian Mousakhan et al, “Anomaly Detection with Conditioned Denoising Diffusion Models,” arxiv 2023.
[9] Marco Rudolph et al, “Same Same But DifferNet: Semi-Supervised Defect Detection with Normalizing Flows,” WACV 2021
[10] Denis Gudovskiy et al, “CFLOW-AD: Real-Time Unsupervised Anomaly Detection with Localization via Conditional Normalizing Flows,” WACV 2022
[11] Thomas Defard et al, “PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization,” ICLR 2020
댓글