https://engineering.linecorp.com/ko/blog/voice-waveform-arbitrary-signal-to-noise-ratio-python/
딥 러닝 음성 인식에 필요한 훈련 데이터를 직접 만들어보자
2022-LINE-engineering-site
engineering.linecorp.com
딥 러닝 음성 인식에 필요한 훈련 데이터를 직접 만들어보자
광고 플랫폼을 개발하는 소프트웨어 엔지니어입니다.
안녕하세요, LINE에서 광고 플랫폼 개발을 맡고 있는 1년차 신입사원 Kunihiko Sato입니다.
이번 블로그에서는 Python을 사용해서 임의의 Signal-to-Noise ratio(SN비)를 가진 음성 파형을 만드는 방법을 소개하겠습니다. 참고로 이 포스팅의 내용은 Clova 등 LINE의 음성 사업과는 관련이 없습니다.
음성 처리 분야에서의 딥 러닝
오래 전 딥 러닝이 이미지 처리 분야에서 기술 혁신을 일으켰는데, 음성 처리 분야에서도 비슷한 일이 벌어지고 있습니다. 딥 러닝으로 음석 인식의 정밀도가 크게 향상되면서, Amazon Echo나 Google Home, LINE Clova와 같은 AI 스피커가 개발되어 시장에 보급되었습니다. 또, 컴퓨터로 음성을 생성하는 문자 음성 변환(Text-to-Speech)의 정밀도도 높아져서 실제 사람의 목소리와 분간하기 힘들 정도의 음질이 되었습니다.
음원 분리에 적용된 딥 러닝
위에서 언급한 사례 외에도 딥 러닝을 통해 정밀도 측면에서 많은 발전을 이룬 음성 처리 분야들이 있는데요. 그 중 하나가 음원 분리입니다.
음원 분리란 여러 개의 음원이 섞여 있는 입력 파형을 개별 음원의 파형으로 분리하는 것을 말합니다. 예를 들어 음성 강조 혹은 잡음 제거라고 말하는, 음성과 잡음이 섞여 있는 입력 파형을 음성 파형과 잡음 파형으로 각각 분리해내는 것이 음원 분리에 해당됩니다. 또는 피아노, 트럼펫, 기타 소리가 섞여 있는 입력 음원을 3개의 파형으로 분리하는 것도 음원 분리라고 부릅니다. 아래 그림은 음원 분리를 이미지로 나타낸 그림입니다.

아래는 딥 러닝을 통해 음원 분리 정밀도가 대폭 향상된 사례들입니다.
딥 러닝에 필요한 훈련 데이터 제작
딥 러닝으로 음원 분리를 구현하려면 학습용 데이터 세트를 준비해야 합니다. 이 포스팅을 보시면 추후 학습용 훈련 데이터 세트가 필요할 때 도움이 될 수 있습니다.
이해를 돕기 위해 이 포스팅에서는 음성 파형에서 잡음을 제거하여 음성만 추출하는 '음성 강조(잡음 제거)' 음원 분리에 대해 살펴 보겠습니다. 먼저, 신경 회로망의 학습을 도식화하면 아래와 같습니다.
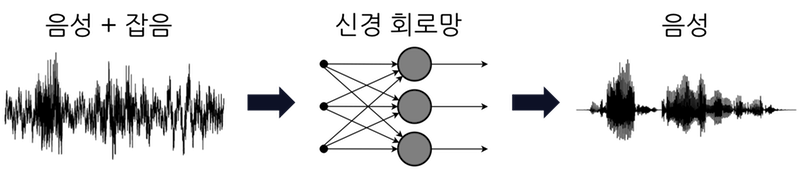
훈련 데이터(training data)에는 음성과 잡음이 섞여 있는 파형이 필요합니다. 또, 교사 데이터(teacher data)에는 음성만 있는 파형이 필요합니다. 이 데이터들을 이용해 신경 회로망은 잡음이 섞여 있는 음성 파형에서 음성만 추출하도록 훈련됩니다.
음성만 있는 데이터 세트로는 TIMIT 코퍼스 등을 비롯해 유명한 음성 코퍼스(말뭉치)들이 여럿 있지만, 잡음이 포함된 음성 데이터와 음성만 있는 데이터를 쌍으로 갖추고 있는 데이터 세트는 별로 없습니다. 따라서, 이미 나와있는 데이터 세트를 활용하는 것만으론 부족할 수 있습니다. 만약 개발자가 임의의 SN비를 가진 파형을 합성할 수 있게 되면, '음성과 잡음' 뿐만 아니라 여러 악기 소리가 혼합된 데이터 세트까지 만들 수 있습니다. 그러면 개발 요건에 맞는 데이터 세트를 각각 필요에 따라 만들 수 있게 되니 이번 기회에 직접 만들 수 있는 방법을 익혀두면 좋을 것 같습니다.
Signal-to-Noise ratio란
Signal-to-Noise ratio(SN비, 신호 대비 잡음 비)란 신호의 크기가 잡음의 크기보다 얼마나 큰지 나타내는 비율입니다. 음성 신호에서 SN비의 단위는 dB(데시벨)입니다. 이 포스팅에서는 Signal을 음성, Noise를 그 외의 소리(화이트 노이즈, 환경음 등)로 설명하겠습니다.
SN비 수치가 높을수록 음성이 잡음보다 크다는 것을 의미합니다. 예를 들어, 5dB일 때보다 20dB일 때가 음성은 크게, 잡음은 작게 들리는 상태입니다. 0dB은 음성과 잡음의 크기가 동일하다는 의미입니다. 음성보다 잡음이 더 큰 경우에는 -10dB과 같은 마이너스 수치가 나옵니다.
'임의의 Signal-to-Noise ratio를 가진 음성 파형을 만든다'는 것은 원하는 dB 비율로 음성과 잡음이 섞여 있는 음성 파형을 만든다는 의미입니다.
Signal-to-Noise ratio 계산 방법
SN비는 다음 계산식으로 구할 수 있습니다.
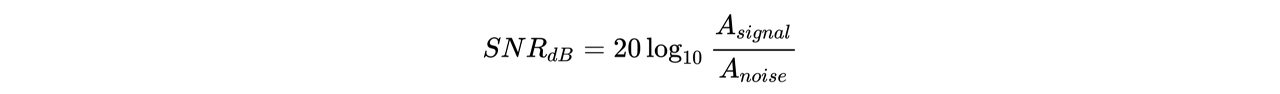
Asignal와 Anoise는 각각 음성과 잡음의 '크기' 혹은 '세기'를 나타냅니다. '세기'의 정의에는 몇 가지가 있는데, 이 포스팅에서는 진폭값의 평균 제곱근(Root Mean Square, RMS)을 각 소리의 세기로 정의하겠습니다.
진폭값의 평균 제곱근은 다음과 같은 순서로 구할 수 있습니다.
- 먼저, 아래 그림처럼 음성의 진폭값이 마이너스 수치로 나올 수도 있으니 진폭값을 제곱합니다.
- 제곱한 값을 더한 뒤 그 값의 평균을 구합니다.
- 마지막으로 평균한 값의 제곱근을 계산하면 소리의 세기를 구할 수 있습니다.

파형 내의 모든 진폭값을 이용한 평균 제곱근 값은 파형에 무음 구간이 많거나 특정 구간만 비정상적으로 진폭값이 큰 경우엔 소리의 세기로 사용할 수 없습니다. 이런 경우, 진폭값의 평균 제곱근이 나타내는 값과 사람이 지각하는 소리의 세기간에 차이가 발생하기 때문에, 무음 구간을 제거하거나 짧은 간격으로 SN비를 계산해야 합니다. 여기에서 소개한 방법 외에도 SN비를 구하는 다른 방법이 있을테니 꼭 조사해 보시기 바랍니다.
Python으로 임의 Signal-to-Noise ratio의 음성 파형 제작
그럼 실제로 음성에 임의 크기의 잡음을 중첩시키는 프로그램을 Python으로 구현해 보겠습니다.
먼저 완성된 코드의 링크를 걸어 두겠습니다.
https://github.com/Sato-Kunihiko/audio-SNR
위 코드에 따라 생성된 음성 예시는 아래와 같습니다.
왼쪽 위부터 차례대로 SN비가 -20, -5, 0, 5, 20dB인 음성 파형입니다. 수치가 커질수록 잡음이 작아지고 음성이 잘 들리게 됩니다.
※위 프로그램을 실행해도 동영상 파일은 생성되지 않으며 음성 파일이 생성됩니다. 이 블로그 사양상 포스팅에 음성 파일을 삽입할 수 없어서 YouTube에 업로드한 동영상을 게재했습니다.
준비
실행 환경 준비
- Python3.x 버전
- MacOS
음성 파일 포맷 확인
음성 파일은 반드시 확장자가 .wav인 파일을 사용해야 합니다. wav 파일의 포맷은 아래와 같이 설정하기 바랍니다.
- 양자화 bit수는 16bit
- 음성용 파일과 잡음용 파일의 샘플링 레이트(sampling rate)를 통일
양자화 bit수는 16bit가 기본값으로 설정되어 있는 경우가 많습니다. 샘플링 레이트는 파일별로 다른 경우가 많으니 유의하시기 바랍니다. (16000Hz나 44100Hz, 48000Hz로 되어 있는 경우가 많습니다.) 샘플링 레이트의 변경은 SoX 등의 음성 편집 소프트웨어를 사용하면 커맨드라인에서도 실행할 수 있습니다.
사용할 데이터 세트 준비
이번 구현에서는 음성만 있는 wav 파일과 잡음만 있는 wav 파일을 사용합니다.
음성만 있는 파일은 CMU ARCTIC 코퍼스를 사용했습니다.
잡음만 있는 파일은 DEMAND를 사용했습니다. DEMAND는 18가지의 환경음이 수록된 데이터 세트입니다.
실행
wav 파일 로딩하기
먼저 wav 파일을 읽어들이도록 구현합니다. Python에서 wav 파일을 취급하기 위한 라이브러리는 몇 가지가 있는데, 이번에는 wave 라이브러리를 사용합니다.
import argparse
import array
import math
import numpy as np
import random
import wave
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--clean_file', type=str, required=True)
parser.add_argument('--noise_file', type=str, required=True)
parser.add_argument('--output_clean_file', type=str, default='')
parser.add_argument('--output_noise_file', type=str, default='')
parser.add_argument('--output_noisy_file', type=str, default='', required=True)
parser.add_argument('--snr', type=float, default='', required=True)
args = parser.parse_args()
return args
if __name__ == '__main__':
args = get_args()
clean_file = args.clean_file
noise_file = args.noise_file
snr = args.snr
clean_wav = wave.open(clean_file, "r")
noise_wav = wave.open(noise_file, "r")
위 Python 코드를 실행할 때는, 아래 인수들이 필요합니다.
- 음성만 있는 파일의 절대 경로--clean_file
- 잡음만 있는 파일의 절대 경로--noise_file
- 처리 완료된 음성만 있는 파일의 절대 경로(옵션)--output_clean_file
- 처리 완료된 잡음만 있는 파일의 절대 경로(옵션)--output_noise_file
- 임의 SN비의 음성 파일의 절대 경로--output_noisy_file
- 합성하려는 SN비의 크기--snr
실제 실행되는 스크립트는 아래와 같습니다. 파일명과 폴더 경로는 각자 환경에 맞는 값으로 바꿔 주세요.
python3 create_noisy_minumum_code.py --clean_file ~/Desktop/test_source/arctic_b0001.wav --noise_file ~/Desktop/test_noise/0ch01.wav --output_clean_file ~/Desktop/clean.wav --output_noise_file ~/Desktop/noise.wav --output_noisy_file ~/Desktop/noisy.wav --snr 0
음성 파형의 진폭값 취득하기
wav 파일을 읽어들여 해당 파일의 진폭값을 얻습니다.
def cal_amp(wf):
buffer = wf.readframes(wf.getnframes())
amptitude = (np.frombuffer(buffer, dtype="int16")).astype(np.float64)
return amptitude
if __name__ == '__main__':
(중략)
clean_amp = cal_amp(clean_wav)
noise_amp = cal_amp(noise_wav)
wf.readframes(n)는 최대 n개의 오디오 프레임을 읽어들여 bytes 객체로 반환합니다. wf.getnframes()는 오디오 프레임 수를 반환합니다. 즉, wf.readframes(wf.getnframes())함수로 wav 파일의 모든 진폭값을 취득할 수 있습니다.마지막으로 bytes 객체를 (np.frombuffer(buffer, dtype="int16")).astype(np.float64)함수를 사용해 np.float64에 캐스팅합니다.
진폭값의 평균 제곱근(Root Mean Square, RMS) 구하기
진폭값의 RMS를 구하기 전에 주의할 점이 있습니다.
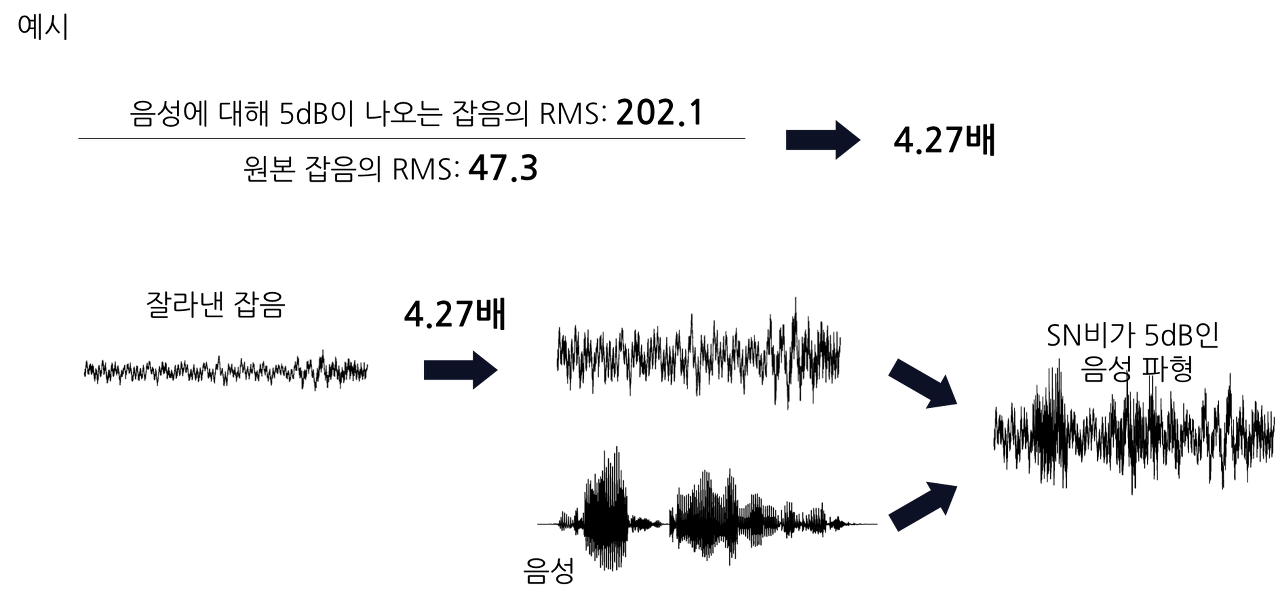
DEMAND의 잡음 데이터는 한 파일당 길이가 5분이고, CMU 코퍼스의 음성 데이터는 한 파일당 길이가 2~5초입니다. 따라서 잡음 데이터 파형을 음성 데이터 파형 길이로 잘라야 합니다. 그리고 아래 그림처럼 원본 잡음 파일에서 잘라낸 파형과 음성 데이터 파형의 RMS를 각각 계산하여 임의 SN비가 나오도록 중첩합니다.
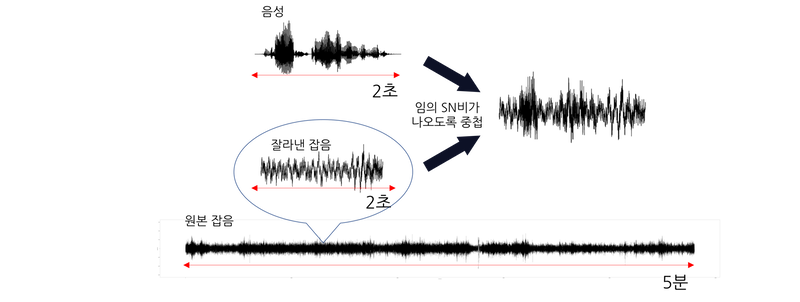
실제 코드에서는 잡음을 자를 위치를 랜덤으로 정해서 음성의 길이만큼 잘라냅니다.
def cal_rms(amp):
return np.sqrt(np.mean(np.square(amp), axis=-1))
if __name__ == '__main__':
(중략)
start = random.randint(0, len(noise_amp)-len(clean_amp))
clean_rms = cal_rms(clean_amp)
split_noise_amp = noise_amp[start: start + len(clean_amp)]
noise_rms = cal_rms(split_noise_amp)
Signal-to-Noise ratio 계산식을 이용해 임의 크기로 파형 합성하기
위에서 말씀드린 것과 같이, SN비 계산식은 다음과 같습니다.
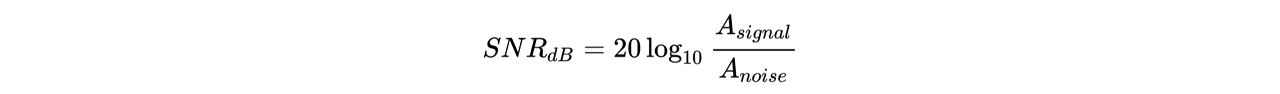
위 계산식을 이용해서 음성에 대해 임의의 SN비가 나오도록 잡음의 RMS를 구합니다. 잡음의 RMS는 위 계산식을 변형한 아래의 계산식으로 구할 수 있습니다.
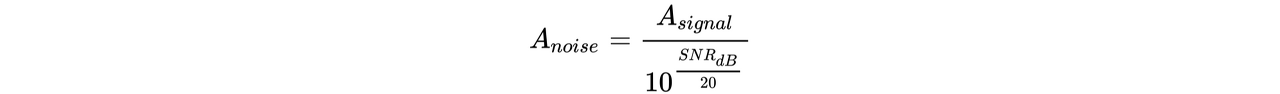
아래 그림과 같이, 위 계산식으로 도출한 RMS(Anoise)와 원본 잡음의 RMS의 비율을 계산하여 그 비율만큼 원본 잡음의 진폭값을 조정합니다. 그 후 조정한 잡음의 진폭과 음성 단독의 진폭을 더합니다.
def cal_adjusted_rms(clean_rms, snr):
a = float(snr) / 20
noise_rms = clean_rms / (10**a)
return noise_rms
if __name__ == '__main__':
(중략)
adjusted_noise_rms = cal_adjusted_rms(clean_rms, snr)
adjusted_noise_amp = split_noise_amp * (adjusted_noise_rms / noise_rms)
mixed_amp = (clean_amp + adjusted_noise_amp)
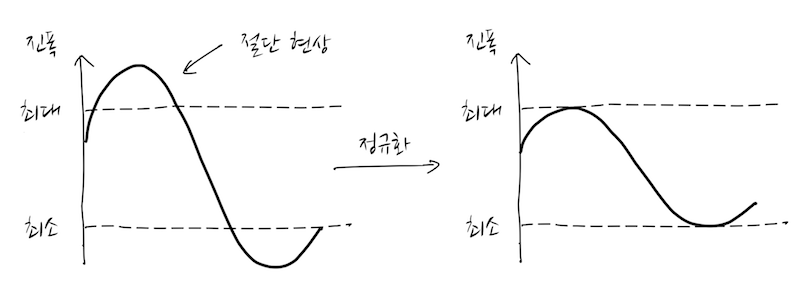
두 진폭을 서로 더한 후에 주의할 점이 있습니다. 각각의 진폭을 더한 진폭값이 wav 파일의 양자화 bit수, 16bit의 최대값(이진수로 32767)을 넘어 버릴 수 있기 때문입니다. 이렇게 되면 최대값을 넘는 파형은 소위 '절단 현상(breaking)을 초래합니다. 따라서, 서로 더한 값이 16bit의 최대값을 넘을 경우, 서로 더한 값의 최대가 32767 안에 들어오도록 정규화합니다.
if (mixed_amp.max(axis=0) > 32767):
mixed_amp = mixed_amp * (32767/mixed_amp.max(axis=0))
clean_amp = clean_amp * (32767/mixed_amp.max(axis=0))
adjusted_noise_amp = adjusted_noise_amp * (32767/mixed_amp.max(axis=0))
파형을 wav 파일로 저장하기
마지막으로 파형을 wav 파일로 저장합니다. wav 파일로 저장할 때도 wave 라이브러리를 사용합니다.
noisy_wave = wave.Wave_write(args.output_noisy_file)
noisy_wave.setparams(clean_wav.getparams())
noisy_wave.writeframes(array.array('h', mixed_amp.astype(np.int16)).tostring() )
noisy_wave.close()
clean_wave = wave.Wave_write(args.output_clean_file)
clean_wave.setparams(clean_wav.getparams())
clean_wave.writeframes(array.array('h', clean_amp.astype(np.int16)).tostring() )
clean_wave.close()
noise_wave = wave.Wave_write(args.output_noise_file)
noise_wave.setparams(clean_wav.getparams())
noise_wave.writeframes(array.array('h', adjusted_noise_amp.astype(np.int16)).tostring() )
noise_wave.close()
setparams()는 wav 파일의 포맷을 지정하는 메서드입니다. 특별한 문제가 없으면 입력에 사용한 음성 파일 포맷을 그대로 사용해도 됩니다.writeframes()로 진폭값을 지정합니다. String에 캐스팅해야 합니다.
전체 코드
마지막으로 전체 코드를 공개합니다. Gihub에도 올려두었습니다.
# -*- coding: utf-8 -*-
import argparse
import array
import math
import numpy as np
import random
import wave
def get_args():
parser = argparse.ArgumentParser()
parser.add_argument('--clean_file', type=str, required=True)
parser.add_argument('--noise_file', type=str, required=True)
parser.add_argument('--output_clean_file', type=str, default='')
parser.add_argument('--output_noise_file', type=str, default='')
parser.add_argument('--output_noisy_file', type=str, default='', required=True)
parser.add_argument('--snr', type=float, default='', required=True)
args = parser.parse_args()
return args
def cal_adjusted_rms(clean_rms, snr):
a = float(snr) / 20
noise_rms = clean_rms / (10**a)
return noise_rms
def cal_amp(wf):
buffer = wf.readframes(wf.getnframes())
amptitude = (np.frombuffer(buffer, dtype="int16")).astype(np.float64)
return amptitude
def cal_rms(amp):
return np.sqrt(np.mean(np.square(amp), axis=-1))
if __name__ == '__main__':
args = get_args()
clean_file = args.clean_file
noise_file = args.noise_file
snr = args.snr
clean_wav = wave.open(clean_file, "r")
noise_wav = wave.open(noise_file, "r")
clean_amp = cal_amp(clean_wav)
noise_amp = cal_amp(noise_wav)
start = random.randint(0, len(noise_amp)-len(clean_amp))
clean_rms = cal_rms(clean_amp)
split_noise_amp = noise_amp[start: start + len(clean_amp)]
noise_rms = cal_rms(split_noise_amp)
adjusted_noise_rms = cal_adjusted_rms(clean_rms, snr)
adjusted_noise_amp = split_noise_amp * (adjusted_noise_rms / noise_rms)
mixed_amp = (clean_amp + adjusted_noise_amp)
if (mixed_amp.max(axis=0) > 32767):
mixed_amp = mixed_amp * (32767/mixed_amp.max(axis=0))
clean_amp = clean_amp * (32767/mixed_amp.max(axis=0))
adjusted_noise_amp = adjusted_noise_amp * (32767/mixed_amp.max(axis=0))
noisy_wave = wave.Wave_write(args.output_noisy_file)
noisy_wave.setparams(clean_wav.getparams())
noisy_wave.writeframes(array.array('h', mixed_amp.astype(np.int16)).tostring() )
noisy_wave.close()
clean_wave = wave.Wave_write(args.output_clean_file)
clean_wave.setparams(clean_wav.getparams())
clean_wave.writeframes(array.array('h', clean_amp.astype(np.int16)).tostring() )
clean_wave.close()
noise_wave = wave.Wave_write(args.output_noise_file)
noise_wave.setparams(clean_wav.getparams())
noise_wave.writeframes(array.array('h', adjusted_noise_amp.astype(np.int16)).tostring() )
noise_wave.close()
마치며
딥 러닝을 통해 다양한 음성 처리의 정밀도가 향상되었지만, 아직 이 분야는 복잡한 사전 지식이 필요하고 참고할만한 문서도 많지 않다고 느껴집니다. 이 포스팅을 보시고 더 많은 분들이 음성 처리에 관심 갖게 되면 좋겠습니다.
포스팅 내용에 오류가 있거나, 다른 의견이 있으시면 Github나 twitter로 연락 부탁드립니다.
긴 글 읽어주셔서 감사합니다.
https://wdprogrammer.tistory.com/43
DSP를 이용한 음성 인식 (speech recognition) 구현 1편 : 음성 데이터 분석
2019-03-12-speech-classification 이 포스팅은 Kaggle Speech representation and data exploration kernel의 데이터 분석 부분을 참고하였다. My kaggle study repository : https://github.com/go1217jo/kaggle..
wdprogrammer.tistory.com
이 포스팅은 Kaggle Speech representation and data exploration kernel의 데이터 분석 부분을 참고하였다.
My kaggle study repository : https://github.com/go1217jo/kaggle_study
항상 학습 모델을 만들기 전에 데이터에 대한 분석이 반드시 이루어져야 한다.
Sampling
임의로 'yes' 라고 말하는 음성 파일 하나를 선택하여 분석해보자. 먼저, wav 파일을 샘플링해야 한다.
from scipy.io import wavfiletrain_audio_path = 'data/train/audio/'filename = 'yes/0a7c2a8d_nohash_0.wav'sample_rate, samples = wavfile.read(train_audio_path + filename)print('sample rate : {}, samples.shape : {}'.format(sample_rate, samples.shape))Result > sample rate : 16000, samples.shape : (16000,)
sample rate ( = sample frequency)가 16000 Hz일 때, sample 수가 16000개이므로 이 음성 파일은 1초 라는 것을 간접적으로 알 수 있다.
Visualization
이 음성 파일을 시각화하여 살펴보자. 음성은 시간, 주파수, 진폭(amplitude)으로 이루어져 있다. 하지만 단순하게 spectrum 그래프를 그리면 이 세 가지 요소를 동시에 살펴볼 수 없다. 그래서 신호의 spectral content의 시간 변위를 표시하는 시간, 주파수에 대한 2차 함수인 Spectrogram을 계산해야 한다.
Spectrogram 함수 정의
from scipy import signalimport numpy as npdef log_specgram(audio, sample_rate, window_size=20, step_size=10, eps=1e-10): # nperseg: Length of each segment # noverlap: Number of points to overlap between segments nperseg = int(round(window_size * sample_rate / 1e3)) noverlap = int(round(step_size * sample_rate / 1e3)) freqs, times, spec = signal.spectrogram(audio, fs=sample_rate, window='hann', nperseg=nperseg, noverlap=noverlap, detrend=False) return freqs, times, np.log(spec.T.astype(np.float32) + eps)
Amplitude, Spectrogram plot 그리기
import matplotlib.pyplot as pltfreqs, times, spectrogram = log_specgram(samples, sample_rate)fig = plt.figure(figsize=(14, 8))ax1 = fig.add_subplot(211)ax1.set_title('Raw wave of ' + filename)ax1.set_ylabel('Amplitude')ax1.plot(np.linspace(0, sample_rate/len(samples), sample_rate), samples)ax2 = fig.add_subplot(212)ax2.imshow(spectrogram.T, aspect='auto', origin='lower', extent=[times.min(), times.max(), freqs.min(), freqs.max()])ax2.set_yticks(freqs[::16])ax2.set_xticks(times[::16])ax2.set_title('Spectrogram of ' + filename)ax2.set_ylabel('Freqs in Hz')ax2.set_xlabel('Seconds')
하지만 많은 좋은 tool이 나와서 다음과 같이 3D 그래프로도 그릴 수 있게 되었다.
import IPython.display as ipdimport plotly.graph_objs as godata = [go.Surface(x=times, y=freqs, z=spectrogram.T)]layout = go.Layout( autosize=False, width=800, height=600, title = 'Spectrogram of "yes" in 3D', scene = dict( yaxis = dict(title='Frequencies', range=[freqs.min(), freqs.max()]), xaxis = dict(title='Time', range=[times.min(), times.max()]), zaxis = dict(title='Log amplitude') ))fig = go.Figure(data=data, layout=layout)py.iplot(fig)
Normalization
이제 spectrogram 값의 범위를 살펴보자.
print('{} ~ {}'.format(spectrogram.min(), spectrogram.max()))Result > -19.381107330322266 ~ 11.731490135192871
값의 분포가 넓기 때문에 훈련 데이터로 사용하기에 적합하지 않다. 따라서 정규분포로 Normalize를 해야 한다.
mean = np.mean(spectrogram, axis=0)std = np.std(spectrogram, axis=0)spectrogram = (spectrogram - mean) / stdspectrogram.shape
Dimensionality Reduction
음성 데이터는 이미지만큼이나 크기가 크다. 그렇기 때문에 훈련 속도를 위해서는 크기를 줄여줄 필요가 있다. 첫 번째로 VAD (Voice Activity Detection)을 시도해보자.
Jupyter 환경에서 다음 코드로 음성을 들을 수 있다.
import IPython.display as ipdipd.Audio(samples, rate=sample_rate)
음성을 들어보면 "yes" 가 명확히 들린다. 하지만 위 그래프에서 amplitude 값들을 보면 중앙에 몰려있고 앞뒤로는 silence가 있다는 것을 알 수 있다. 그래서 silence를 삭제해서 데이터 크기를 줄일 수 있다.
# 0.25 ~ 0.8125 * sample_rate(16000)samples_cut = samples[4000:13000]ipd.Audio(samples_cut, rate=sample_rate)
앞뒤로 음성을 잘랐음에도 불구하고 "yes"가 잘 들리는 것을 확인할 수 있다.
그렇지만 수동으로 자르기에는 한계가 있다. 그러니 webrtcvad를 이용해서 자동으로 잘라보는 것을 해보자.
import webrtcvadvad = webrtcvad.Vad()# 1~3 까지 설정 가능, 높을수록 aggressivevad.set_mode(3)class Frame(object): """Represents a "frame" of audio data.""" def __init__(self, bytes, timestamp, duration): self.bytes = bytes self.timestamp = timestamp self.duration = durationdef frame_generator(frame_duration_ms, audio, sample_rate): frames = [] n = int(sample_rate * (frame_duration_ms / 1000.0) * 2) offset = 0 timestamp = 0.0 duration = (float(n) / sample_rate) / 2.0 while offset + n < len(audio): frames.append(Frame(audio[offset:offset + n], timestamp, duration)) timestamp += duration offset += n return frames# 10, 20, or 30frame_duration_ms = 10 # msframes = frame_generator(frame_duration, samples, sample_rate)for i, frame in enumerate(frames): if not vad.is_speech(frame.bytes, sample_rate): print(i, end=' ')Result > 0 1 2 3 4 5 6 7 8 9 10 11 12 13 36 37 38 39 40 41 42 43 44 45 46 47 48
음성으로 인식되지 않는 인덱스를 출력해본 것인데 중간에 인덱스 간격이 큰 곳이 바로 음성이 집중되어 있는곳이라 할 수 있다. 이대로 잘라본 것을 들어보자.
samples_cut = samples[4480:11755]ipd.Audio(samples_cut, rate=sample_rate)
꽤나 만족스러운 결과를 들을 수 있었다. 이제 자동으로 음성 파일 내 silence를 자르는 함수를 만들어보자.
def auto_vad(vad, samples, sample_rate, frame_duration_ms = 10): not_speech = [] frames = frame_generator(frame_duration_ms, samples, sample_rate) n_frame = len(frames) for idx, frame in enumerate(frames): if not vad.is_speech(frame.bytes, sample_rate): not_speech.append(idx) prior = 0 cutted_samples = [] for i in not_speech: if i - prior > 2: start = int((float(prior) / n_frame) * sample_rate) end = int((float(i) / n_frame) * sample_rate) print(start, end) if len(cutted_samples) == 0: cutted_samples = samples[start:end] else: cutted_samples = np.append(cutted_samples, samples[start:end]) prior = i return cutted_samplescutted_samples = auto_vad(vad, samples, sample_rate, 10)ipd.Audio(cutted_samples, rate=sample_rate)Result > 4244 12081
제대로 "yes" 가 들리는 것을 확인할 수 있다. 이제 spectrogram으로도 한 번 확인해보자.
freqs, times, spectrogram = log_specgram(cutted_samples, sample_rate)fig,ax = plt.subplots(1)ax.imshow(spectrogram.T, aspect='auto', origin='lower', extent=[times.min(), times.max(), freqs.min(), freqs.max()])ax.set_yticks(freqs[::16])ax.set_xticks(times[::16])ax.set_title('Spectrogram of ' + filename)ax.set_ylabel('Freqs in Hz')ax.set_xlabel('Seconds')
두 번째 방법으로는 resampling이 있다. 현재 sample rate는 16000 Hz이다. 만약 8000 Hz 정도로 resample하면 어떻게 될까?
당연히 아무런 문제가 없다. 왜냐하면 speech와 많이 관계된 주파수는 대부분 낮은 대역대에 존재하기 때문이다.
filename = 'happy/0b09edd3_nohash_0.wav'new_sample_rate = 8000sample_rate, samples = wavfile.read(str(train_audio_path) + filename)resampled = signal.resample(samples, int(new_sample_rate/sample_rate * samples.shape[0]))
이어지는 포스팅에서는 데이터셋에 대한 분석이 이루어지며, 최종적으로 학습 모델 구성을 해볼 것이다.
https://dbstndi6316.tistory.com/328?category=957031
[머신러닝 공부] Tiny ML -10 / 음성인식 모델훈련하기 -1
Chapter10. 음성인식(호출어 감지) 모델 훈련하기 " 새로운 모델을 만들어보자 " 목차 : 새로운 모델 훈련 프로젝트에서 모델 사용 모델 작동 방식 -> 다음장 내 데이터로 훈련하기 -> 다음장 새로운
dbstndi6316.tistory.com
Chapter10. 음성인식(호출어 감지) 모델 훈련하기
"
새로운 모델을 만들어보자
"
목차 :
- 새로운 모델 훈련
- 프로젝트에서 모델 사용
- 모델 작동 방식 -> 다음장
- 내 데이터로 훈련하기 -> 다음장
새로운 모델 훈련 :
우선 이 장에서는 yes, no 외의 다른 단어를 인식할 수 있는 모델을 훈련할 것이다.
훈련 시 아래와 같은 사항을 고려해야 될 것이다.
- 입력 : 기존 스크립트 활용을 위해 데이터의 모양과 형식을 맞춰줘야 한다.
- 출력 : 클래스 당 하나의 확률 텐서 타입을 갖는 출력을 맞춰줘야 한다.
- 훈련데이터 : 많은 데이터는 정확도를 향상시킨다.
- 최적화문제 : 메모리가 극도로 제한된 상태이므로 최적화문제가 있다.
참고한 기존 스크립트는 아래 스크립트이다.
GitHub - tensorflow/tflite-micro: TensorFlow Lite for Microcontrollers
TensorFlow Lite for Microcontrollers. Contribute to tensorflow/tflite-micro development by creating an account on GitHub.
github.com
※ 공부를 계속하며 레포지토리가 계속 최신화 되어 책의 설명과 안맞는 부분이 있는데 위 링크도 그렇다.
최신 코드를 반영한 레포지토리는 아래 링크이다.
(https://www.tensorflow.org/tutorials/audio/simple_audio)
> 이후 '런타임 - 런타임 유형 변경' 에서 하드웨어 가속을 GPU로 설정해준다.
(6개월 전만 해도 Colab Pro+ 버전에서 백그라운드 실행 같은 기능은 없었던것 같은데.. 너무 혜택이 없어서 그런지 추가해줬나보다.)
> 해당 주피터노트북을 실행하면 데이터셋을 자동으로 다운받는다.
아래와 같은 wav 데이터들이 학습데이터로 주어진다.

> 이번엔 yes, no 가 아닌 on, off를 훈련시켜보자.
또한 학습률 0.001로 12000번 학습을, 0.0001로 3000번 학습을 시켜보자.
학습초반엔 높은 학습률로 iter를 수행해 빠르게 수렴을 진행하고 이후엔 가중치와 편향을 미세하게 조정할것이다.
WANTED_WORDS = "on,off"
TRAINING_STEPS = "12000,3000"
LEARNING_RATE = "0.001,0.0001"
> Environment Setup을 실행하고 훈련을 시작한다.
!python tensorflow/tensorflow/examples/speech_commands/train.py \
--data_dir={DATASET_DIR} \
--wanted_words={WANTED_WORDS} \
--silence_percentage={SILENT_PERCENTAGE} \
--unknown_percentage={UNKNOWN_PERCENTAGE} \
--preprocess={PREPROCESS} \
--window_stride={WINDOW_STRIDE} \
--model_architecture={MODEL_ARCHITECTURE} \
--how_many_training_steps={TRAINING_STEPS} \
--learning_rate={LEARNING_RATE} \
--train_dir={TRAIN_DIR} \
--summaries_dir={LOGS_DIR} \
--verbosity={VERBOSITY} \
--eval_step_interval={EVAL_STEP_INTERVAL} \
--save_step_interval={SAVE_STEP_INTERVAL}
> tensorboard가 잘 로드되었다면 아래와 같이 훈련중 결과들이 보드에 나타날 것이다.

> 훈련 중 음성 입력데이터에 대한 스펙트로그램을 IMAGES 탭에서 볼 수 있다.

> 약 두 시간 후 훈련이 완료된 후의 tensorboard 모습이다.

> smoothing을 높게 주었을 때 train data에 대한 accuracy 와 cross_entropy 그래프이다.

> 마찬가지로 smoothing을 높게 주었을 때 validation data에 대한 accuracy 와 cross_entropy 그래프이다.

> freezing 과정 : 파이썬 스크립트와 체크포인트 파일들을 하나의 모델파일로 통합하여 추론에 사용할 수 있게 한다.
가중치가 고정된 정적인 그래프를 만들어보자.
!python tensorflow/tensorflow/examples/speech_commands/freeze.py \
--wanted_words=$WANTED_WORDS \
--window_stride_ms=$WINDOW_STRIDE \
--preprocess=$PREPROCESS \
--model_architecture=$MODEL_ARCHITECTURE \
--start_checkpoint=$TRAIN_DIR$MODEL_ARCHITECTURE'.ckpt-'{TOTAL_STEPS} \
--save_format=saved_model \
--output_file={SAVED_MODEL}
생성된 파일은 완전히 훈련된 파일로 추론을 실행하는 데 사용할 수 있다.
다만 이는 TFlite 가 아닌 일반 tensorflow 방식이므로 MCU에 이식하기 위해서는 변환이 필요하다.
> 텐서플로 라이트로 변환하기
- lite로 변환한다는 것은 곧 양자화 한다는 것
optimization 방식, inference input, inference output 의 type, sampling rate 등을 지정해주고 converter를 이용해 변환해준다.
SAMPLE_RATE = 16000
CLIP_DURATION_MS = 1000
WINDOW_SIZE_MS = 30.0
FEATURE_BIN_COUNT = 40
BACKGROUND_FREQUENCY = 0.8
BACKGROUND_VOLUME_RANGE = 0.1
TIME_SHIFT_MS = 100.0
DATA_URL = 'https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.02.tar.gz'
VALIDATION_PERCENTAGE = 10
TESTING_PERCENTAGE = 10model_settings = models.prepare_model_settings(
len(input_data.prepare_words_list(WANTED_WORDS.split(','))),
SAMPLE_RATE, CLIP_DURATION_MS, WINDOW_SIZE_MS,
WINDOW_STRIDE, FEATURE_BIN_COUNT, PREPROCESS)
audio_processor = input_data.AudioProcessor(
DATA_URL, DATASET_DIR,
SILENT_PERCENTAGE, UNKNOWN_PERCENTAGE,
WANTED_WORDS.split(','), VALIDATION_PERCENTAGE,
TESTING_PERCENTAGE, model_settings, LOGS_DIR)with tf.Session() as sess:
float_converter = tf.lite.TFLiteConverter.from_saved_model(SAVED_MODEL)
float_tflite_model = float_converter.convert()
float_tflite_model_size = open(FLOAT_MODEL_TFLITE, "wb").write(float_tflite_model)
print("Float model is %d bytes" % float_tflite_model_size)
converter = tf.lite.TFLiteConverter.from_saved_model(SAVED_MODEL)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.inference_input_type = tf.lite.constants.INT8
converter.inference_output_type = tf.lite.constants.INT8
def representative_dataset_gen():
for i in range(100):
data, _ = audio_processor.get_data(1, i*1, model_settings,
BACKGROUND_FREQUENCY,
BACKGROUND_VOLUME_RANGE,
TIME_SHIFT_MS,
'testing',
sess)
flattened_data = np.array(data.flatten(), dtype=np.float32).reshape(1, 1960)
yield [flattened_data]
converter.representative_dataset = representative_dataset_gen
tflite_model = converter.convert()
tflite_model_size = open(MODEL_TFLITE, "wb").write(tflite_model)
print("Quantized model is %d bytes" % tflite_model_size)

결과적으로 모델의 크기는 18712bytes로 매우 작아졌음을 확인할 수 있다.
> 양자화 이후 모델의 accuracy를 test 해본다.

성능이 조금은 떨어질 것이라고 생각했지만 이상하게도 accuracy가 더 높게 나왔다.
> C 배열 만들기
xxd 커맨드를 이용해 모델을 C배열로 변환하는 작업이다.
이 배열을 MCU에 이식해 동작을 확인해볼 것이다.
# Install xxd if it is not available
!apt-get update && apt-get -qq install xxd
# Convert to a C source file
!xxd -i {MODEL_TFLITE} > {MODEL_TFLITE_MICRO}
# Update variable names
REPLACE_TEXT = MODEL_TFLITE.replace('/', '_').replace('.', '_')
!sed -i 's/'{REPLACE_TEXT}'/g_model/g' {MODEL_TFLITE_MICRO}명령을 실행한 후 !cat {MODEL_TF_LITE_MICRO} 명령으로 배열을 확인해볼 수 있다.

프로젝트에서 모델 사용
> 위에서 모델 훈련 후 만들어진 모델을 C배열 형태로 바꾸었으니 MCU에 이식해보자.
책에서는 위 C배열을 micro_features/tiny_conv_micro_features_model_data.cc 내용에 붙여넣으라고 하나
또! 버전이 다른 관계로 내가 clone 한 버전에서는 micro_features/model.cc로 대체되었다. (자주 버전이 바뀌나보다..)
> 그 다음은 label을 업데이트 해 줄 차례이다.
micro_features/micro_model_settings.cc를 열어 label을 변경해준다. (yes,no -> on,off)

> command_responder.cc 업데이트
on,off 가 들릴 때 어떤 LED 출력을 낼지에 대한 동작을 정의해 주는 부분이다.
tensorflow/lite/micro/examples/micro_speech/sparkfun_edge/command_responder.cc 를 수정한다.
am_devices_led_toggle(am_bsp_psLEDs, AM_BSP_LED_BLUE);
am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_RED);
am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_YELLOW);
am_devices_led_off(am_bsp_psLEDs, AM_BSP_LED_GREEN);
if (is_new_command) {
TF_LITE_REPORT_ERROR(error_reporter, "Heard %s (%d) @%dms", found_command,
score, current_time);
if (found_command[0] == 'o' && found_command[1] == 'n') {
am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_YELLOW);
}
if (found_command[0] == 'o' && found_command[1] == 'f') {
am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_RED);
}
if (found_command[0] == 'u') {
am_devices_led_on(am_bsp_psLEDs, AM_BSP_LED_GREEN);
}
}
> 역시 한번에 될리는 없다.
make -f tensorflow/lite/micro/tools/make/Makefile TARGET=sparkfun_edge micro_speech_bin위 명령을 실행해보니

이런 에러가 떴고 model.cc에서 unsigned int g_model_len 을 const int g_model_len 으로 변경하고 make 진행
tensorflow/lite/micro/tools/make/gen/spark~micro/bin/micro_speech.bin위 경로에 bin 파일이 생성되었다.
> 바이너리 서명
cp tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/keys_info0.py tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/keys_info.pypython3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/create_cust_image_blob.py --bin tensorflow/lite/micro/tools/make/gen/sparkfun_edge_cortex-m4_micro/bin/micro_speech.bin --load-address 0xC000 --magic-num 0xCB -o main_nonsecure_ota --version 0x0python3 tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/create_cust_wireupdate_blob.py --load-address 0x20000 --bin main_nonsecure_ota.bin -i 6 -o main_nonsecure_wire --options 0x1위 명령으로 main_nonsecure_wire.bin 파일이 생성되었고 이를 플래시 할 것이다.
> 디바이스 연결 및 설정
export DEVICENAME=/dev/ttyUSB0
export BAUD_RATE=921600sudo chmod 666 /dev/ttyUSB0
> 플래싱
python tensorflow/lite/micro/tools/make/downloads/AmbiqSuite-Rel2.2.0/tools/apollo3_scripts/uart_wired_update.py -b ${BAUD_RATE} ${DEVICENAME} -r 1 -f main_nonsecure_wire.bin -i 6
on이라고 말하면 노란색 LED가, off를 말하면 빨간색 LED가 켜질 것이다.
Google Colab 외의 다른 방법으로 스크립트를 실행하기
colab을 써보신 분이라면 연결이 끊겨 짜증나는 경험을 한번씩 해보셨을것이라 생각한다.
이에 아래와 같은 방법들을 사용할 수 있다.
로컬 워크스테이션에 도커를 올려 사용하는 방식은 내 GPU가 좋지않아 해보지 못하겠지만 google cloud에서 training 후 inference server와 연동하는 방법은 조만간 배워보려한다.
- GPU가 있는 클라우드 가상머신
Deep Learning VM Image | 딥 러닝 VM 이미지 | Google Cloud
딥 러닝 애플리케이션을 위해 사전 구성된 VM입니다.
cloud.google.com
- 로컬 워크스테이션 with 텐서플로 GPU 도커 이미지
Docker | TensorFlow
Help protect the Great Barrier Reef with TensorFlow on Kaggle Join Challenge Docker Docker는 컨테이너를 사용하여 TensorFlow 설치를 나머지 시스템에서 격리하는 가상 환경을 만듭니다. TensorFlow 프로그램은 호스트 머
www.tensorflow.org
'Python' 카테고리의 다른 글
| 10 minutes to pandas (0) | 2023.01.10 |
|---|---|
| 이미지 처리와 텍스트 인식 python pillow & tesseract (0) | 2022.09.20 |
| Paiza Cloud IDE (0) | 2022.07.21 |
| Kalman Filter Recap (0) | 2022.07.21 |
| ESP-EYE driver installation & web-esphome (0) | 2022.07.21 |



댓글