https://www.tensorflow.org/tutorials/audio/simple_audio
간단한 오디오 인식: 키워드 인식 | TensorFlow Core
이 자습서에서는 WAV 형식의 오디오 파일을 사전 처리하고 10개의 다른 단어를 인식하기 위한 기본 자동 음성 인식 (ASR) 모델을 구축 및 훈련하는 방법을 보여줍니다. "down", "go", "left", "no", "와 같
www.tensorflow.org
간단한 오디오 인식: 키워드 인식
이 자습서에서는 WAV 형식의 오디오 파일을 사전 처리하고 10개의 다른 단어를 인식하기 위한 기본 자동 음성 인식 (ASR) 모델을 구축 및 훈련하는 방법을 보여줍니다. "down", "go", "left", "no", "와 같은 명령의 짧은(1초 이하) 오디오 클립이 포함된 Speech Commands 데이터 세트 ( Warden, 2018 )의 일부를 사용할 것입니다. 오른쪽", "중지", "위" 및 "예".
실제 음성 및 오디오 인식 시스템 은 복잡합니다. 그러나 MNIST 데이터 세트를 사용한 이미지 분류와 마찬가지로 이 튜토리얼은 관련된 기술에 대한 기본적인 이해를 제공해야 합니다.
설정
필요한 모듈 및 종속성을 가져옵니다. 이 튜토리얼에서는 시각화를 위해 seaborn 을 사용할 것입니다.
import os
import pathlib
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from IPython import display
# Set the seed value for experiment reproducibility.
seed = 42
tf.random.set_seed(seed)
np.random.seed(seed)
미니 음성 명령 데이터 세트 가져오기
데이터 로드 시간을 절약하기 위해 더 작은 버전의 Speech Commands 데이터 세트로 작업하게 됩니다. 원본 데이터 세트 는 35개의 다른 단어를 말하는 사람들의 WAV(Waveform) 오디오 파일 형식 으로 된 105,000개 이상의 오디오 파일로 구성됩니다. 이 데이터는 Google에서 수집했으며 CC BY 라이선스에 따라 배포했습니다.
tf.keras.utils.get_file을 사용하여 더 작은 음성 명령 데이터 세트가 포함된 mini_speech_commands.zip 파일을 다운로드하고 압축을 tf.keras.utils.get_file .
DATASET_PATH = 'data/mini_speech_commands'
data_dir = pathlib.Path(DATASET_PATH)
if not data_dir.exists():
tf.keras.utils.get_file(
'mini_speech_commands.zip',
origin="http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip",
extract=True,
cache_dir='.', cache_subdir='data')
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/mini_speech_commands.zip
182083584/182082353 [==============================] - 1s 0us/step
182091776/182082353 [==============================] - 1s 0us/step
데이터 세트의 오디오 클립은 각 음성 명령에 해당하는 8개의 폴더( no , yes , down , go , left , up , right 및 stop )에 저장됩니다.
commands = np.array(tf.io.gfile.listdir(str(data_dir)))
commands = commands[commands != 'README.md']
print('Commands:', commands)
Commands: ['stop' 'left' 'no' 'go' 'yes' 'down' 'right' 'up']
오디오 클립을 filenames 라는 목록으로 추출하고 섞습니다.
filenames = tf.io.gfile.glob(str(data_dir) + '/*/*')
filenames = tf.random.shuffle(filenames)
num_samples = len(filenames)
print('Number of total examples:', num_samples)
print('Number of examples per label:',
len(tf.io.gfile.listdir(str(data_dir/commands[0]))))
print('Example file tensor:', filenames[0])
Number of total examples: 8000
Number of examples per label: 1000
Example file tensor: tf.Tensor(b'data/mini_speech_commands/yes/db72a474_nohash_0.wav', shape=(), dtype=string)
filenames 을 각각 80:10:10 비율을 사용하여 훈련, 검증 및 테스트 세트로 분할합니다.
train_files = filenames[:6400]
val_files = filenames[6400: 6400 + 800]
test_files = filenames[-800:]
print('Training set size', len(train_files))
print('Validation set size', len(val_files))
print('Test set size', len(test_files))
Training set size 6400
Validation set size 800
Test set size 800
오디오 파일 및 해당 레이블 읽기
이 섹션에서는 데이터 세트를 사전 처리하여 파형 및 해당 레이블에 대한 디코딩된 텐서를 생성합니다. 참고:
- 각 WAV 파일에는 초당 샘플 수가 설정된 시계열 데이터가 포함되어 있습니다.
- 각 샘플은 특정 시간의 오디오 신호 진폭 을 나타냅니다.
- 미니 음성 명령 데이터 세트의 WAV 파일과 같은 16비트 시스템에서 진폭 값의 범위는 -32,768에서 32,767입니다.
- 이 데이터 세트의 샘플 속도 는 16kHz입니다.
tf.audio.decode_wav 가 반환하는 텐서의 모양은 [samples, channels] 입니다. 여기서 channels 은 모노의 경우 1 이고 스테레오의 경우 2 입니다. 미니 음성 명령 데이터 세트에는 모노 녹음만 포함됩니다.
test_file = tf.io.read_file(DATASET_PATH+'/down/0a9f9af7_nohash_0.wav')
test_audio, _ = tf.audio.decode_wav(contents=test_file)
test_audio.shape
TensorShape([13654, 1])
이제 데이터 세트의 원시 WAV 오디오 파일을 오디오 텐서로 전처리하는 함수를 정의해 보겠습니다.
def decode_audio(audio_binary):
# Decode WAV-encoded audio files to `float32` tensors, normalized
# to the [-1.0, 1.0] range. Return `float32` audio and a sample rate.
audio, _ = tf.audio.decode_wav(contents=audio_binary)
# Since all the data is single channel (mono), drop the `channels`
# axis from the array.
return tf.squeeze(audio, axis=-1)
각 파일의 상위 디렉토리를 사용하여 레이블을 생성하는 함수를 정의합니다.
- 파일 경로를 tf.RaggedTensor 로 분할합니다(비정형 차원의 텐서 - 길이가 다를 수 있는 슬라이스 포함).
def get_label(file_path):
parts = tf.strings.split(
input=file_path,
sep=os.path.sep)
# Note: You'll use indexing here instead of tuple unpacking to enable this
# to work in a TensorFlow graph.
return parts[-2]
모든 것을 하나로 묶는 또 다른 도우미 함수 get_waveform_and_label 을 정의합니다.
- 입력은 WAV 오디오 파일 이름입니다.
- 출력은 지도 학습을 위해 준비된 오디오 및 레이블 텐서를 포함하는 튜플입니다.
def get_waveform_and_label(file_path):
label = get_label(file_path)
audio_binary = tf.io.read_file(file_path)
waveform = decode_audio(audio_binary)
return waveform, label
오디오 레이블 쌍을 추출하도록 훈련 세트를 빌드합니다.
- 앞에서 정의한 get_waveform_and_label 을 사용하여 Dataset.from_tensor_slices 및 Dataset.map 으로 tf.data.Dataset 을 만듭니다.
나중에 유사한 절차를 사용하여 검증 및 테스트 세트를 빌드합니다.
AUTOTUNE = tf.data.AUTOTUNE
files_ds = tf.data.Dataset.from_tensor_slices(train_files)
waveform_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
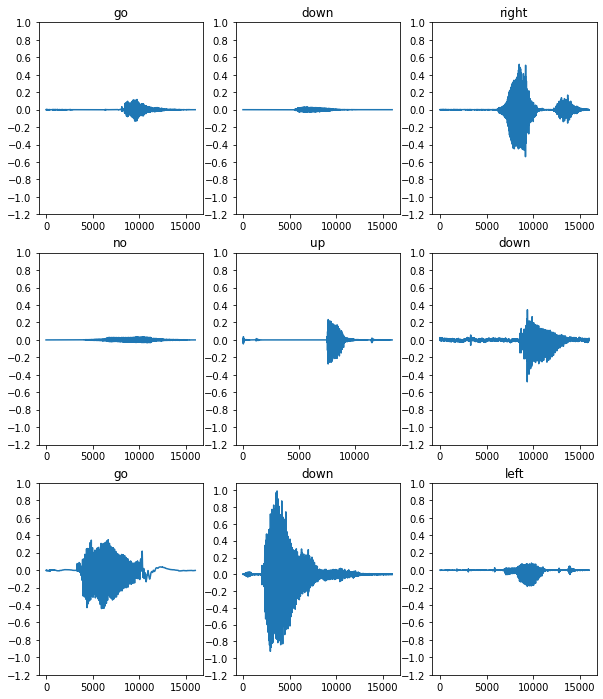
몇 가지 오디오 파형을 플로팅해 보겠습니다.
rows = 3
cols = 3
n = rows * cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 12))
for i, (audio, label) in enumerate(waveform_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
ax.plot(audio.numpy())
ax.set_yticks(np.arange(-1.2, 1.2, 0.2))
label = label.numpy().decode('utf-8')
ax.set_title(label)
plt.show()
파형을 스펙트로그램으로 변환
데이터 세트의 파형은 시간 영역에서 표시됩니다. 다음으로, STFT(단시간 푸리에 변환) 를 계산하여 파형을 시간에 따른 주파수 변화를 보여주고 다음과 같이 나타낼 수 있는 스펙트로그램 으로 변환하여 시간 영역 신호의 파형을 시간 주파수 영역 신호로 변환합니다. 2D 이미지로 표현됩니다. 스펙트로그램 이미지를 신경망에 공급하여 모델을 훈련시킵니다.
푸리에 변환( tf.signal.fft )은 신호를 구성 요소 주파수로 변환하지만 모든 시간 정보는 손실됩니다. 이에 비해 STFT( tf.signal.stft )는 신호를 시간 창으로 분할하고 각 창에서 푸리에 변환을 실행하여 일부 시간 정보를 보존하고 표준 컨볼루션을 실행할 수 있는 2D 텐서를 반환합니다.
파형을 스펙트로그램으로 변환하기 위한 유틸리티 함수 생성:
- 파형의 길이가 같아야 스펙트로그램으로 변환할 때 결과가 비슷한 차원을 갖게 됩니다. 이것은 1초보다 짧은 오디오 클립을 단순히 제로 패딩( tf.zeros 사용)하여 수행할 수 있습니다.
- tf.signal.stft 를 호출할 때 생성된 스펙트로그램 "이미지"가 거의 정사각형이 되도록 frame_length 및 frame_step 매개변수를 선택하십시오. STFT 매개변수 선택에 대한 자세한 내용은 오디오 신호 처리 및 STFT에 대한 Coursera 비디오 를 참조하십시오.
- STFT는 크기와 위상을 나타내는 복소수 배열을 생성합니다. 그러나 이 자습서에서는 tf.abs 의 출력에 tf.signal.stft 를 적용하여 파생할 수 있는 크기만 사용합니다.
def get_spectrogram(waveform):
# Zero-padding for an audio waveform with less than 16,000 samples.
input_len = 16000
waveform = waveform[:input_len]
zero_padding = tf.zeros(
[16000] - tf.shape(waveform),
dtype=tf.float32)
# Cast the waveform tensors' dtype to float32.
waveform = tf.cast(waveform, dtype=tf.float32)
# Concatenate the waveform with `zero_padding`, which ensures all audio
# clips are of the same length.
equal_length = tf.concat([waveform, zero_padding], 0)
# Convert the waveform to a spectrogram via a STFT.
spectrogram = tf.signal.stft(
equal_length, frame_length=255, frame_step=128)
# Obtain the magnitude of the STFT.
spectrogram = tf.abs(spectrogram)
# Add a `channels` dimension, so that the spectrogram can be used
# as image-like input data with convolution layers (which expect
# shape (`batch_size`, `height`, `width`, `channels`).
spectrogram = spectrogram[..., tf.newaxis]
return spectrogram
다음으로 데이터 탐색을 시작합니다. 한 예의 텐서화된 파형과 해당 스펙트로그램의 모양을 인쇄하고 원본 오디오를 재생합니다.
for waveform, label in waveform_ds.take(1):
label = label.numpy().decode('utf-8')
spectrogram = get_spectrogram(waveform)
print('Label:', label)
print('Waveform shape:', waveform.shape)
print('Spectrogram shape:', spectrogram.shape)
print('Audio playback')
display.display(display.Audio(waveform, rate=16000))
Label: yes
Waveform shape: (16000,)
Spectrogram shape: (124, 129, 1)
Audio playback
이제 스펙트로그램을 표시하는 함수를 정의합니다.
def plot_spectrogram(spectrogram, ax):
if len(spectrogram.shape) > 2:
assert len(spectrogram.shape) == 3
spectrogram = np.squeeze(spectrogram, axis=-1)
# Convert the frequencies to log scale and transpose, so that the time is
# represented on the x-axis (columns).
# Add an epsilon to avoid taking a log of zero.
log_spec = np.log(spectrogram.T + np.finfo(float).eps)
height = log_spec.shape[0]
width = log_spec.shape[1]
X = np.linspace(0, np.size(spectrogram), num=width, dtype=int)
Y = range(height)
ax.pcolormesh(X, Y, log_spec)
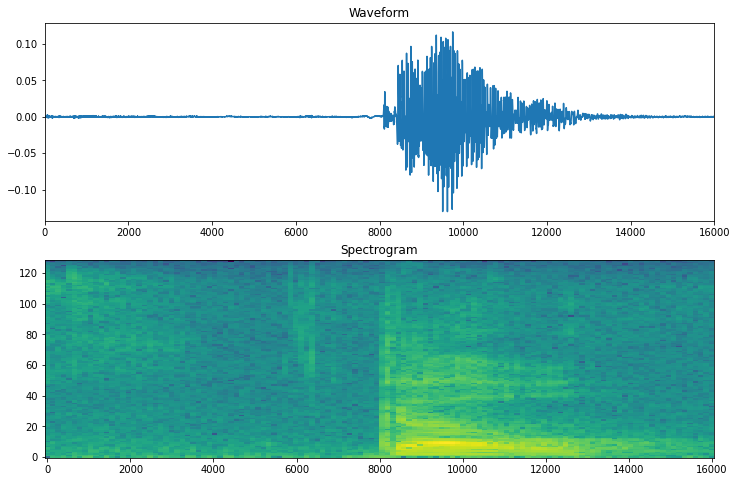
시간에 따른 예제의 파형과 해당 스펙트로그램(시간에 따른 주파수)을 플로팅합니다.
fig, axes = plt.subplots(2, figsize=(12, 8))
timescale = np.arange(waveform.shape[0])
axes[0].plot(timescale, waveform.numpy())
axes[0].set_title('Waveform')
axes[0].set_xlim([0, 16000])
plot_spectrogram(spectrogram.numpy(), axes[1])
axes[1].set_title('Spectrogram')
plt.show()
이제 파형 데이터 세트를 스펙트로그램으로 변환하고 해당 레이블을 정수 ID로 변환하는 함수를 정의합니다.
def get_spectrogram_and_label_id(audio, label):
spectrogram = get_spectrogram(audio)
label_id = tf.argmax(label == commands)
return spectrogram, label_id
get_spectrogram_and_label_id 을 사용하여 데이터 세트의 요소 전체에 Dataset.map 를 매핑합니다.
spectrogram_ds = waveform_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
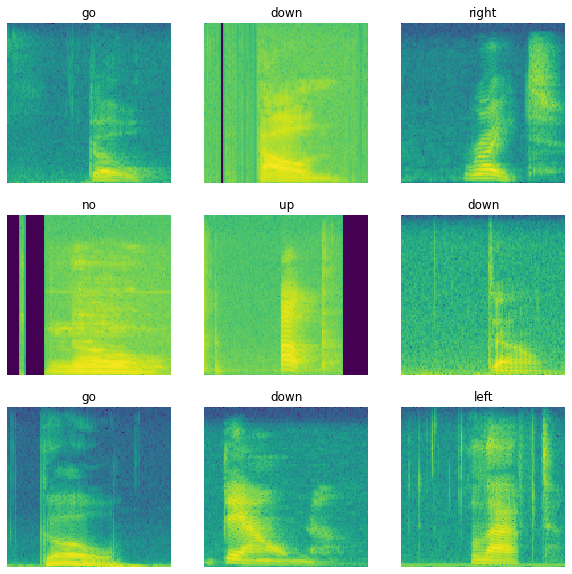
데이터 세트의 다양한 예에 대한 스펙트로그램을 조사합니다.
rows = 3
cols = 3
n = rows*cols
fig, axes = plt.subplots(rows, cols, figsize=(10, 10))
for i, (spectrogram, label_id) in enumerate(spectrogram_ds.take(n)):
r = i // cols
c = i % cols
ax = axes[r][c]
plot_spectrogram(spectrogram.numpy(), ax)
ax.set_title(commands[label_id.numpy()])
ax.axis('off')
plt.show()
모델 빌드 및 학습
검증 및 테스트 세트에 대해 훈련 세트 전처리를 반복합니다.
def preprocess_dataset(files):
files_ds = tf.data.Dataset.from_tensor_slices(files)
output_ds = files_ds.map(
map_func=get_waveform_and_label,
num_parallel_calls=AUTOTUNE)
output_ds = output_ds.map(
map_func=get_spectrogram_and_label_id,
num_parallel_calls=AUTOTUNE)
return output_ds
train_ds = spectrogram_ds
val_ds = preprocess_dataset(val_files)
test_ds = preprocess_dataset(test_files)
모델 훈련을 위한 훈련 및 검증 세트를 일괄 처리합니다.
batch_size = 64
train_ds = train_ds.batch(batch_size)
val_ds = val_ds.batch(batch_size)
Dataset.cache 및 Dataset.prefetch 작업을 추가하여 모델을 훈련하는 동안 읽기 지연 시간을 줄입니다.
train_ds = train_ds.cache().prefetch(AUTOTUNE)
val_ds = val_ds.cache().prefetch(AUTOTUNE)
이 모델의 경우 오디오 파일을 스펙트로그램 이미지로 변환했으므로 간단한 CNN(컨볼루션 신경망)을 사용합니다.
tf.keras.Sequential 모델은 다음과 같은 Keras 전처리 레이어를 사용합니다.
- tf.keras.layers.Resizing : 모델이 더 빠르게 학습할 수 있도록 입력을 다운샘플링합니다.
- tf.keras.layers.Normalization : 평균과 표준편차를 기반으로 이미지의 각 픽셀을 정규화합니다.
Normalization 계층의 경우 집계 통계(즉, 평균 및 표준 편차)를 계산하기 위해 먼저 훈련 데이터에서 해당 adapt 메서드를 호출해야 합니다.
for spectrogram, _ in spectrogram_ds.take(1):
input_shape = spectrogram.shape
print('Input shape:', input_shape)
num_labels = len(commands)
# Instantiate the `tf.keras.layers.Normalization` layer.
norm_layer = layers.Normalization()
# Fit the state of the layer to the spectrograms
# with `Normalization.adapt`.
norm_layer.adapt(data=spectrogram_ds.map(map_func=lambda spec, label: spec))
model = models.Sequential([
layers.Input(shape=input_shape),
# Downsample the input.
layers.Resizing(32, 32),
# Normalize.
norm_layer,
layers.Conv2D(32, 3, activation='relu'),
layers.Conv2D(64, 3, activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.25),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dropout(0.5),
layers.Dense(num_labels),
])
model.summary()
Input shape: (124, 129, 1)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
resizing (Resizing) (None, 32, 32, 1) 0
normalization (Normalizatio (None, 32, 32, 1) 3
n)
conv2d (Conv2D) (None, 30, 30, 32) 320
conv2d_1 (Conv2D) (None, 28, 28, 64) 18496
max_pooling2d (MaxPooling2D (None, 14, 14, 64) 0
)
dropout (Dropout) (None, 14, 14, 64) 0
flatten (Flatten) (None, 12544) 0
dense (Dense) (None, 128) 1605760
dropout_1 (Dropout) (None, 128) 0
dense_1 (Dense) (None, 8) 1032
=================================================================
Total params: 1,625,611
Trainable params: 1,625,608
Non-trainable params: 3
_________________________________________________________________
Adam 옵티마이저와 교차 엔트로피 손실을 사용하여 Keras 모델을 구성합니다.
model.compile(
optimizer=tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'],
)
데모 목적으로 10개 에포크에 걸쳐 모델 훈련:
EPOCHS = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=EPOCHS,
callbacks=tf.keras.callbacks.EarlyStopping(verbose=1, patience=2),
)
Epoch 1/10
100/100 [==============================] - 6s 41ms/step - loss: 1.7503 - accuracy: 0.3630 - val_loss: 1.2850 - val_accuracy: 0.5763
Epoch 2/10
100/100 [==============================] - 0s 5ms/step - loss: 1.2101 - accuracy: 0.5698 - val_loss: 0.9314 - val_accuracy: 0.6913
Epoch 3/10
100/100 [==============================] - 0s 5ms/step - loss: 0.9336 - accuracy: 0.6703 - val_loss: 0.7529 - val_accuracy: 0.7325
Epoch 4/10
100/100 [==============================] - 0s 5ms/step - loss: 0.7503 - accuracy: 0.7397 - val_loss: 0.6721 - val_accuracy: 0.7713
Epoch 5/10
100/100 [==============================] - 0s 5ms/step - loss: 0.6367 - accuracy: 0.7741 - val_loss: 0.6061 - val_accuracy: 0.7975
Epoch 6/10
100/100 [==============================] - 0s 5ms/step - loss: 0.5650 - accuracy: 0.7987 - val_loss: 0.5489 - val_accuracy: 0.8125
Epoch 7/10
100/100 [==============================] - 0s 5ms/step - loss: 0.5099 - accuracy: 0.8183 - val_loss: 0.5344 - val_accuracy: 0.8238
Epoch 8/10
100/100 [==============================] - 0s 5ms/step - loss: 0.4560 - accuracy: 0.8392 - val_loss: 0.5194 - val_accuracy: 0.8288
Epoch 9/10
100/100 [==============================] - 0s 5ms/step - loss: 0.4101 - accuracy: 0.8547 - val_loss: 0.4809 - val_accuracy: 0.8388
Epoch 10/10
100/100 [==============================] - 0s 5ms/step - loss: 0.3905 - accuracy: 0.8589 - val_loss: 0.4973 - val_accuracy: 0.8363
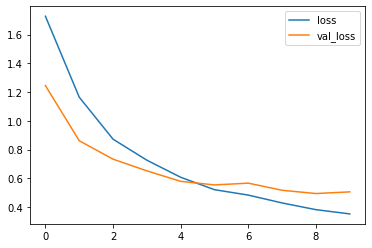
학습 및 검증 손실 곡선을 플롯하여 학습 중에 모델이 어떻게 개선되었는지 확인하겠습니다.
metrics = history.history
plt.plot(history.epoch, metrics['loss'], metrics['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.show()
모델 성능 평가
테스트 세트에서 모델을 실행하고 모델의 성능을 확인합니다.
test_audio = []
test_labels = []
for audio, label in test_ds:
test_audio.append(audio.numpy())
test_labels.append(label.numpy())
test_audio = np.array(test_audio)
test_labels = np.array(test_labels)
y_pred = np.argmax(model.predict(test_audio), axis=1)
y_true = test_labels
test_acc = sum(y_pred == y_true) / len(y_true)
print(f'Test set accuracy: {test_acc:.0%}')
Test set accuracy: 85%
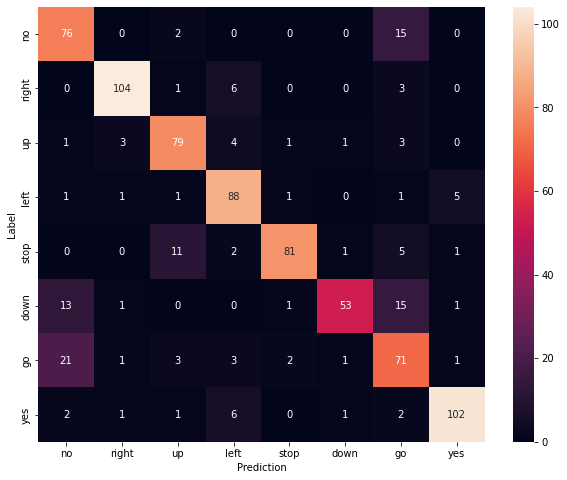
정오분류표 표시
혼동 행렬 을 사용하여 모델이 테스트 세트의 각 명령을 얼마나 잘 분류했는지 확인하십시오.
confusion_mtx = tf.math.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(10, 8))
sns.heatmap(confusion_mtx,
xticklabels=commands,
yticklabels=commands,
annot=True, fmt='g')
plt.xlabel('Prediction')
plt.ylabel('Label')
plt.show()
오디오 파일에 대한 추론 실행
마지막으로 "아니오"라고 말하는 사람의 입력 오디오 파일을 사용하여 모델의 예측 출력을 확인합니다. 모델의 성능은 어느 정도입니까?
sample_file = data_dir/'no/01bb6a2a_nohash_0.wav'
sample_ds = preprocess_dataset([str(sample_file)])
for spectrogram, label in sample_ds.batch(1):
prediction = model(spectrogram)
plt.bar(commands, tf.nn.softmax(prediction[0]))
plt.title(f'Predictions for "{commands[label[0]]}"')
plt.show()
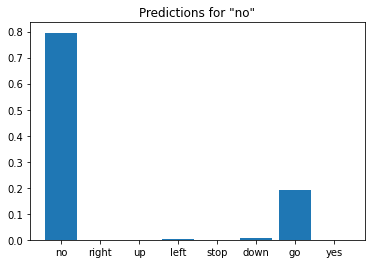
출력에서 알 수 있듯이 모델은 오디오 명령을 "아니오"로 인식해야 합니다.
다음 단계
이 튜토리얼은 TensorFlow 및 Python과 함께 컨벌루션 신경망을 사용하여 간단한 오디오 분류/자동 음성 인식을 수행하는 방법을 보여주었습니다. 자세히 알아보려면 다음 리소스를 고려하세요.
- YAMNet을 사용한 사운드 분류 튜토리얼은 오디오 분류를 위해 전이 학습을 사용하는 방법을 보여줍니다.
- Kaggle의 TensorFlow 음성 인식 챌린지 에서 나온 노트북입니다.
- TensorFlow.js - 전이 학습 코드랩을 사용한 오디오 인식 은 오디오 분류를 위한 대화형 웹 앱을 직접 구축하는 방법을 알려줍니다.
- arXiv 의 음악 정보 검색을 위한 딥 러닝 튜토리얼 (Choi et al., 2017).
- 또한 TensorFlow는 자체 오디오 기반 프로젝트를 지원하기 위해 오디오 데이터 준비 및 보강 에 대한 추가 지원을 제공합니다.
- 음악 및 오디오 분석을 위한 Python 패키지인 librosa 라이브러리 사용을 고려하십시오.
'Python' 카테고리의 다른 글
| [Python] 파이썬 학습사이트 (0) | 2022.06.19 |
|---|---|
| MNIST-dataset-in-different-formats (0) | 2022.06.13 |
| jupyter notebook : kernel error (0) | 2022.06.11 |
| 파이썬으로 구글 Gmail 보내기 1편. SMTP의 개념과 구글 앱 비밀번호 발급받기 (0) | 2022.06.10 |
| 판다스 데이터 추가하기: 파이썬 excel 자동화 openpyxl (0) | 2022.05.26 |

댓글