https://cafe.naver.com/openiot
열린 사물인터넷 : 네이버 카페
오픈소스 하드웨어,라즈베리파이,아두이노,esp8266,소프트웨어,리눅스,파이썬을 활용한 사물인터넷
cafe.naver.com
이번에는 요즘 각광을 받고 있는 음성인식(Voice Recognition)과 인공지능 가상 비서(Artificial Intelligent Virtual Assistant)에 대하여 알아보자.
먼저 라즈베리파이에서 음성 파일을 변환하거나 출력하기 위해서는 리눅스 시스템의 사운드 시스템에 대해 알 필요가 있다. 리눅스에서는 커널 2.4 버전까지는 OSS(Open Sound System)라는 사운드 드라이버 모듈을 사용하였고 이후 2.6 버전부터 ALSA(Advanced Linux Sound Architecture) 사운드 드라이버 모듈을 지원하고 있다.
또한, 응용 프로그램에서 사운드 처리를 원활하게 할 수 있게 해 주는 몇 가지 사운드 시스템 미들웨어들이 있다. libasound 는 ALSA 시스템용 API를 제공하는 C 언어 라이브러리이다. 한편 수많은 응용 프로그램에서 활용하는 PortAudio 라는 크로스플랫폼 오픈소스 오디오 입출력 라이브러리도 있다. 그 밖에 네트워크 기능을 지원하는 사운드 서버들도 있다. PulseAudio는 다양한 오디오 소스 입력과 출력을 지원하는 사운드 서버이며, Jack Audio Connection Kit 는 오디오 녹음, 효과, 합성을 위한 저지연 오디오 서버인 jackd 를 포함한다.
라즈베리파이에 오디오 입력 및 출력 장치를 연결하고 테스트해 보자. 마이크는 USB웹캠에 내장된 마이크나 알리익스프레스에서 2-3달러하는 USB 마이크를 사용하면 되고, PC 스피커를 3.5mm 잭에 연결하면 된다.
라즈베리파이에서 오디오 입력 장치를 확인하려면 다음과 같은 명령을 입력하면 된다.
$ arecord -l
**** List of CAPTURE Hardware Devices ****
card 1: Ddvice [USB PnP Sound Device], device:0 USB Audio [USB Audio]
Subdevices: 1/1
Subdevice #0: subdevice #0
오디오 출력 장치를 확인하려면 다음과 같은 명령을 입력한다.
$ aplay -l
**** List of PLAYBACK Hardware Devices ****
card 0: ALSA [bcm2835 ALSA], device 0: bcm2835 ALSA [bcm2835 ALSA]
…
card 0: ALSA [bcm2835 ALSA], device 1: bcm2835 ALSA [bcm2835 IEC958/HDMI]
…
라즈베리파이는 기본적으로 3.5mm 아날로그 잭과 HDMI인 2개의 오디오 출력 장치를 가진다. 장치를 선택하려면 다음 명령을 입력하면 된다. 여기서 n 값으로는 0은 자동(오토), 1은 3.5mm 아날로그 잭, 2는 HDMI 을 지정한다.
$ amixer cset numid=3 <n>
참고로 오디오 입출력 장치의 볼륨을 조절하려면 amixer를 사용해도 되지만 alsamixer를 사용해도 되고 되고 Pulseaudio 서버를 쓰고 있다면 pavucontrol이라는 GUI 프로그램도 사용 가능하다.
$ alsamixer
또한 간단한 스피커 테스트는 다음 명령을 입력하면 된다.
$ speaker-test -t wav
다음은 음성인식, 합성 등을 프로그래밍하기 위해 기본적인 음성 녹음 기능을 테스트해 보자.먼저 마이크를 통해 음성을 녹음하는 기능을 테스트해 본다. 다음과 같은 명령을 입력하면 된다. 여기서 -d 옵션은 녹음시간(초)을 나타낸다.
$ arecord -d 3 temp.wav
만약 여기서 arecord: main:722: audio open error: 그런 파일이나 디렉토리가 없습니다” 와 같은 오류가 나타나면 다음과 같은 .asoundrc 설정 파일을 만들어 준다. 이 파일에서는 재생(playback)을 위한 스피커는 3.5mm 잭(card 0)을 사용하고 녹음(record)을 위한 마이크는 USB 마이크(card 1)을 사용하도록 지정한다. 그리고 마이크에 따라 녹음 파일 형식을 16비트로 지정하지 않으면 잡음이 생길 수도 있다는 점을 주의한다.
$ nano ~/.asoundrc
pcm.!default {
type asym
playback.pcm {
type plug
slave.pcm “hw:0,0”
}
capture.pcm {
type plug
slave.pcm “hw:1,0”
slave.format “S16_LE”
}
}
다음은 녹음된 wav 파일을 재생해 보자. 다음 명령을 입력하고 스피커로부터 음성이 나오는지 확인한다.
$ aplay temp.wav
음성을 듣고 음성으로 응답해 주는 이러한 시스템은 보통 다음과 같은 구조로 이루어져 있다. 먼저 사람의 음성을 마이크로 입력받아 파일로 녹음하고 반대로 파일을 스피커로 출력할 수 있어야 한다. 이런 기능은 라즈베리파이에서는 주로 리눅스 커널의 ALSA 프레임워크와 PulseAudio, PortAudio 와 같은 음성 처리 라이브러리들이 담당한다. 다음 단계에서는 음성 파일을 텍스트로 변환하는 음성 인식, 즉 STT(Speech-To-Text) 기능을 통해 내부 시스템으로 전달된다. 이 텍스트는 인공지능 비서 또는 챗봇 등과 같은 가상 비서 프로그램을 통해 IoT 장치를 자동으로 제어하거나 응답 텍스트를 TTS(Text-To-Speech)로 보낸다. TTS는 텍스트를 음성 파일로 변환하는 음성 합성 기능이며 최종적으로 스피커로 음성을 출력시키게 된다.
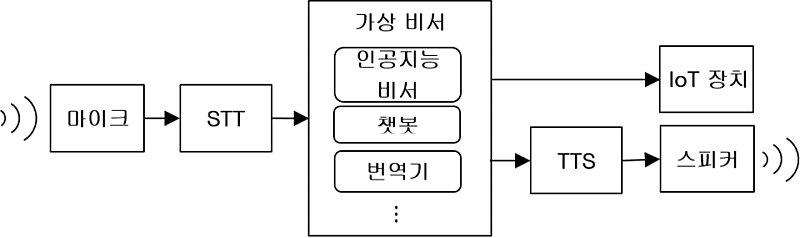
<음성인식, 합성 및 가상비서 시스템>
$ git clone https://github.com/swkim01/virtual-assistant
음성 인식(Speech Recognition)이란 컴퓨터를 사용하여 음성을 텍스트로 인식하고 변역하는 기술을 말하며 다른 말로는 STT(Speech To Text)라고 한다. 음성 인식 시스템의 구조는 다음과 같다. 마이크를 통해 입력된 음성 신호는 PCM(pulse code modulation) 형식의 데이터로 저장되고 이 음향 데이터를 필터링한 특성 벡터를 얻는다. 음향 분석 단계에서는 학습과 통계학적인 분석을 통해 만들어진 음향 모델(Acoustic Model)을 통해 이 특성 벡터를 음성의 기본 단위인 음소(phoneme)으로 분류한다. 다음으로 검색 단계에서는 개별 단어들을 모은 사전과 이들 개별 단어들과 문법에 따른 통계적인 확률을 학습한 언어 모델을 통해 가장 가능성이 높은 단어들과 문장을 찾아낸다. 참고로 음향 모델과 언어 모델에 많이 쓰이는 기술로는 HMM(Hidden Markov Model), DTW(Dynamic Time Warping), NN(Neural Network) 등이 있다. 또한 FST(Finite State Transducer)는 음향 모델과 언어 모델을 통계적으로 결합한다.
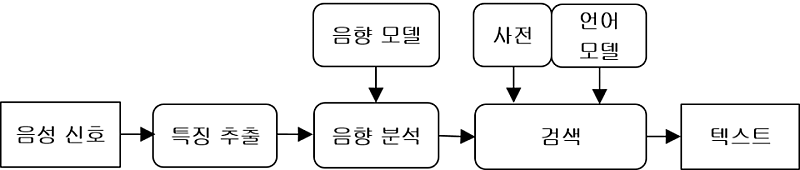
<음성인식 시스템>
대표적인 음성 인식 프로그램으로는 Sphinx/Pocketsphinx, Julius, HTK, Kaldi, MS Windows Speech API(cloud), Google Speech API(cloud), Wit.ai 등이 있다.
다음은 음성 인식 소프트웨어를 설치하고 테스트해 보자.
1) 포켓 스핑크스
먼저 Pocketsphinx는 CMU에서 개발한 오픈 소스 음성 인식 소프트웨어인 Sphinx의 경량 버전이다. 스핑크스는 라이브러리, 음향 모델 및 샘플 프로그램들로 이루어져 있으며, 추가적으로 음향 모델 훈련 프로그램, 컴파일된 언어 모델과 cmudict 발음 사전 및 어휘집을 포함한다.
포켓 스핑크스를 사용하기 위해서는 음향 모델, 언어 모델 및 단어 사전 또는 문법 파일이 필요하다. 음향 모델은 HMM(은닉 마르코프 모델)로 구성하는데, 직접 녹음된 음성 파일을 이용하여 훈련하고 빌드할 수도 있고 이미 빌드된 기존의 모델 파일들을 활용할 수도 있다. 기존의 음향 모델로는 영어, 프랑스어 등에 대한 음향 모델 파일이 있으며 다음 싸이트에서 다운로드할 수 있다.
직접 HMM 모델을 위해 음성 파일을 훈련하고 빌드하는 과정은 까다로우므로 여기서는 이미 빌드된 음향 모델을 활용하기로 한다. 다음 명령을 입력하여 미국 영어에 대한 음향 모델을 다운로드한다.
$ wget https://downloads.sourceforge.net/project/cmusphinx/Acoustic%20and%20Language%20Models/US%20English/cmusphinx-en-us-ptm-5.2.tar.gz
$ tar xvfz cmusphinx-en-us-ptm-5.2.tar.gz
다음은 언어 모델과 어휘 사전을 만들어야 한다. 어휘 사전을 만드는 방법은 phonetisaurus 또는 CMU에서 제공하는 g2p-seq2seq를 이용하는 방법도 가능하지만 여기서는 언어 모델과 함께 만들어 볼 것이다.
포켓스핑크스에서 사용할 수 있는 언어 모델로는 키워드 목록, 문법(grammer) 파일, 통계학적인 언어 모델을 활용할 수 있다. 키워드 목록은 키워드와 함께 사용 빈도를 목록으로 만들어 사용한다. 문법 방식은 jsgf 형식의 문법 파일을 작성하여 활용하는 방식인데, 단어 순서에 대한 확률 대신 문법을 활용하므로 엄격한 문장 인식에 대한 장단점이 각각 존재한다. 마지막으로 통계적 언어 모델은 단어와 단어 순서에 대한 확률을 통해 문장을 추정하므로 복잡하고 유연한 언어 모델이 가능하여 많이 활용된다. 포켓스핑크스에서는 SRILM, CMUCLMTK, MITLM 등의 도구 프로그램이나 웹 서비스를 통해 ARPA 형식의 LM 텍스트 파일이나 BIN 바이너리 파일로 된 언어 모델을 만들 수 있다. 여기서는 포켓스핑크스 웹 싸이트에서 제공하는 웹 서비스를 통하여 통계적 언어 모델을 만들어 보자.
먼저 어휘 사전 및 언어 모델을 위해 다음과 같이 테스트로 사용할 문장을 나열한 corpus.txt 파일을 만든다. 그런데, 언어 모델을 생성하는 도구는 영어 모델에 대해서만 가능하므로 ‘안녕’ 대신 ‘annyong’와 같이 써야 한다.
$ nano corpus.txt
hello
hi pi
annyong
do e-mail
search ...
...
다음은 lmtool 웹 싸이트로 접속하여 corpus.txt 파일을 첨부하여 생성된 언어 모델과 단어 사전을 추출해서 다운로드한다.
생성된 파일은 확장자가 dic인 어휘 사전과 lm, bin 등의 언어 모델 파일들로 구성된다.
...
8521.dic 1.3K Pronunciation Dictionary
8521.lm 8.3K Language Model
…
8521.vocab 390 Word List
TAR8521.tgz 3.7K COMPRESSED TARBALL
다음은 pocketsphinx_continuous라는 포켓스핑크스 유틸리티 프로그램을 사용하여 음성 인식을 테스트해 보자. 먼저 다음 명령으로 pocketsphinx 패키지를 설치한다.
$ sudo apt-get install pocketsphinx
이제 다음과 같은 명령을 실행한다. 참고로 이 명령에서 HMM 음향 모델을 지정하지 않으면 /usr 또는 /usr/local/share/pocketsphinx에 설치된 기본 음향 모델을 사용할 것이다.
$ pocketsphinx_continuous -inmic yes -hmm cmusphinx-en-us-ptm-5.2 -lm 8521.lm -dict 8521.dic
…
... Ready
..
마이크에 ‘hello’ 등을 말한 다음 조금 기다리면 인식된 결과를 출력할 것이다.
다음은 포켓 스핑크스를 파이썬 프로그램으로 테스트해 보자. 먼저 포켓 스핑크스 파이썬 모듈을 설치하기 위해 의존 패키지들을 설치한다.
$ sudo apt-get install -y python python-dev python-pip build-essential swig git libpulse-dev
포켓 스핑크스 파이썬 모듈은 다음 명령으로 설치한다.
$ sudo pip install pocketsphinx
여기서, 포켓 스핑크스 파이썬 모듈을 빌드하려면 sphinxbase와 pocketsphinx 패키지를 필요로 하는데, pip로 설치하면 도중에 함께 빌드하여 사용하므로 이들 패키지를 따로 설치할 필요는 없다.
다음은 마이크 입력을 받아 음성 데이터로 사용하기 위해 pyaudio 모듈을 설치한다.
$ sudo apt-get install portaudio19-dev python-all-dev python3-all-dev
$ sudo pip install pyaudio # or sudo pip3 install pyaudio
PyAudio 파이썬 모듈은 크로스플랫폼 오디오 입출력 라이브러리인 PortAudio의 파이썬 바인딩 모듈이다. pyaudio를 사용하여 프로그래밍하는 방법은 비교적 간단하다. 먼저 pyaudio.PyAudio() 객체를 생성한 후에 open() 메소드로 음성 입력 스트림을 열고 read(), write(), start_stream(), stop_stream() 등의 메소드를 활용하여 음성 녹음, 재생 등의 동작을 수행한다. 마지막으로 close(), terminate() 로 종료하면 된다.
이제 다음과 같은 프로그램을 작성한다.
$ nano psphinxtest.py
import sys
from pocketsphinx import *
import pyaudio
import time
hmm = 'cmusphinx-en-us-ptm-5.2/'
dic = 'dictionary.dic'
lm = 'language_model.lm'
grammar = 'grammar.jsgf'
bufsize = 512
# Create a decoder with certain model
config = Decoder.default_config()
config.set_string('-hmm', hmm)
config.set_string('-lm', lm)
config.set_string('-dict', dic)
# Predetermined grammar file can be used in place of languagel model.
#config.set_string('-jsgf', grammar)
decoder = Decoder(config)
pyAudio = pyaudio.PyAudio()
def getCommand(debug=False):
global pyAudio, bufsize, decoder
# We're going to set up the stream from pyAudio that well be using to get the user's speech from the microphone.
stream = pyAudio.open(format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=bufsize)
# Let the use know that we're ready for them to speak
print('Need more input: ')
# This is a flag that we'll use in a bit to determine whether we are going from silence to speech
# or from speech to silence.
utteranceStarted = False
# This will tell PocketSphinx to start decoding the "utterance". When we are finished with our audio
# we will tell PocketSphinx that the utterance is over.
decoder.start_utt()
# We want this to loop for as long as it takes to get the full sentence from the user. We only exit with a
# return statement when we have our best guess of what the person said.
while True:
try:
# This takes a small sound bite from the microphone to process.
buf = stream.read(bufsize)
except Exception as e:
pass
# If we've got something from the microphone, we should begin processing it.
if buf:
decoder.process_raw(buf, False, False)
inSpeech = decoder.get_in_speech()
# The following checks for the transition from silence to speech.
# We're going to set a flag to reflect this.
if inSpeech and not utteranceStarted:
utteranceStarted = True
# The following checks for the transition from speech to silence.
# This is our cue to check what was said and do something useful with it.
if not inSpeech and utteranceStarted:
# We tell PocketSphinx that the user is finished saying what they wanted
# to say, and that it should makes it's best guess as to what thay was.
decoder.end_utt()
# The following will get a hypothesis object with, amongst other things,
# the string of words that PocketSphinx thinks the user said.
hypothesis = decoder.hyp()
if hypothesis is not None:
bestGuess = hypothesis.hypstr
print('I just heard you say:"{}"'.format(bestGuess))
# We are done with the microphone for now so we'll close the stream.
#stream.stop_stream()
stream.close()
# We have what we came for! A string representing what the user said.
# We'll now return it to the runMain function so that it can be
# processed and some meaning can be gleamed from it.
return bestGuess
# The following is here for debugging to see what the decoder thinks we're saying as we go
if debug and decoder.hyp() is not None:
print(decoder.hyp().hypstr)
if __name__ == '__main__':
while True:
try:
command = getCommand().lower()
print(command)
time.sleep(1)
except (KeyboardInterrupt, SystemExit):
sys.exit()
프로그램을 실행하고 마이크에 “hello”, “annyong” 등의 말을 해 보고 결과를 인식하는지 살펴본다.
$ python psphinxtest.py
3) 구글 음성인식 API
구글 음성 인식 API는 음성 정보를 네트워크를 통해 구글 서버로 전송하여 인식 결과를 전달받는 API이다. 이것은 웹 HTTP 방식의 구글 스피치(Speech) API와 웹 HTTP 및 gRPC(구글이 만든 통신 프로토콜의 일종) 방식의 구글 클라우드 스피치(Cloud Speech) API의 2가지 방식이 있는데, 둘 다 한글이 가능하지만 클라우드 스피치 API의 인식 성능이 더 뛰어나다.
다음은 구글 스피치(Speech) API v2를 사용해 보자. 구글 클라우드 스피치가 공개되기 전에는 크롬에서 지원하는 구글 스피치 API v2를 사용할 수 있었다.
라즈베리파이에서 구글 스피치 API v2를 사용하는 스크립트를 사용해 보자. 먼저 다음과 같은 명령을 입력하여 소스코드를 다운로드한다..
$ git clone https://github.com/StevenHickson/PiAUISuite
내부 디렉토리로 이동한 다음 쉘 스크립트 파일에서 lang 변수를 “ko-KR”(한국어)로 변경한다.
$ cd PiAUISuite/VoiceCommand
$ nano ./speech-recog.sh
…
lang=”ko-KR”
...
arecord -D $hardware -t wav -d $duration -r 16000 | flac - -f --best --sample-rate 16000 -o /dev/shm/out.flac 1>/dev/shm/voice.log 2>/dev/shm/voice.log; curl -X POST --data-binary @/dev/shm/out.flac --user-agent 'Mozilla/5.0' --header 'Content-Type: audio/x-flac; rate=16000;' "https://www.google.com/speech-api/v2/recognize?output=json&lang=$lang&key=AIzaSyBOti4mM-6x9WDnZIjIeyEU21OpBXqWBgw&client=Mozilla/5.0" | sed -e 's/[{}]/''/g' | awk -F":" '{print $4}' | awk -F"," '{print $1}' | tr -d '\n'
스크립트를 보면 알겠지만 마이크로 입력된 음성 데이터는 RAM 공유 메모리 영역(/dev/shm)에 저장된 wave 파일로 저장되고, flac 프로그램을 통해 flac 형식의 파일로 변환된 후에 웹 POST HTTP 요청으로 구글 서버로 전송된다. 여기서 구글 스피치 API v2에서 지원하는 음성 파일 형식인 FLAC 등이므로 FLAC 소프트웨어를 설치해야 한다.
$ sudo apt-get install flac
이제 스크립트를 실행하고 마이크에 “안녕” 이라고 말해본다. 조금 시간이 지난 후에 “안녕” 메시지가 나타나면 제대로 인식된 것이다.
$ ./speech-recog.sh
다음은 구글 클라우드 스피치(Cloud Speech) API를 사용해 보자. 구글 클라우드 스피치 API를 사용하는 방법은 다음과 같다. 먼저 구글 클라우드(https://cloud.google.com)에 로그인한 후 콘솔로 간다. 상단 메뉴의 가운데에 있는 프로젝트 목록에서 이미 만들어진 프로젝트를 선택하거나 프로젝트 만들기 항목을 선택하여 프로젝트를 생성한다. 다음은 상단 메뉴의 왼쪽 탭에서 API 관리자 항목을 선택한 후 이동한다. 왼쪽의 라이브러리 항목을 선택한 후 오른쪽 화면에서 Speech API를 선택한다. 화면 위쪽의 사용 설정 메뉴를 선택하여 Speech API 사용을 활성화한다. 그런데 여기서 결제 계정을 지정되지 않았으면 지정해야 한다는 메시지가 나온다. 결제 계정이 등록되지 않았으면 상단 메뉴의 왼쪽 탭에서 결제 항목을 선택한 후 결제 계정을 등록하고 생성한 프로젝트가 결제 계정에 연동되었는지 확인한다.
다음으로 응용 프로그램에서 구글 클라우드 API를 사용하기 위해서는 사용자 인증을 받아야 하는데, 인증받는 방법은 API 키를 사용하는 방법, 서비스 계정을 활용하는 방법, 사용자 계정을 활용하는 방법의 3가지가 있다. 가장 간단한 방법은 API 키를 생성하고 이용하는 방법이지만 보안 문제가 있으므로 서비스 계정을 사용하는 것이 바람직하다.
먼저 API 키를 사용하여 음성 인식을 해 보자. API 키는 구글 클라우드 콘솔의 프로젝트 창에서 상단 메뉴의 왼쪽 탭에서 I AM 및 관리자 항목을 선택한 후 이동한다. 왼쪽의 사용자 인증 정보 항목을 선택한 후에 “사용자 인증 정보 만들기” 버튼을 클릭하고 API 키를 선택하면 된다. 생성된 API 키를 복사해 둔다.
다음 명령을 실행하고 “안녕하세요”와 같은 간단한 문장을 녹음한다. 여기서, 녹음 시간은 3초이며 샘플링 주기는 16000Hz이다.
$ arecord -d 3 -r 16000 hello.wav
구글 클라우드 스피치 API에서 활용 가능한 형식 중 FLAC 형식을 사용해 보자. 다음 명령을 입력하여 앞서 녹음한 파일을 flac 형식으로 변경한다. hello.flac 파일이 생성되었는지 확인한다.
$ flac -f --best --sample-rate 16000 hello.wav
웹 HTTP 요청 방식의 클라우드 스피치 API를 사용하기 위해 필요한 json 파일의 형식은 다음과 같다. 여기서 config 항목은 음성 데이터 파일의 인코딩, 샘플링 주기, 언어 등의 음성 파일 형식을 나타내고, audio 항목은 음성 데이터를 나타낸다. audio 항목은 content 또는 uri 라는 세부 항목을 지정할 수 있는데, content는 직접 음성 데이터를 포함시킬 때 사용하고, uri는 음성 파일에 대한 URI 링크를 지정할 수 있다. 예를 들면 URI 값으로 gs://cloud-samples-tests/speech/brooklyn.flac는 구글 클라우드에 저장된 음성 파일을 가리킨다.
$ nano hello.json
{
"config": {
"encoding":"FLAC",
"sampleRateHertz": 16000,
"languageCode": "ko-KR"
},
"audio": {
"content":"<데이터스트림>"
"uri":"<음성 파일 링크>"
}
}
이제 직접 음성 파일을 첨부해 보자. 그런데, FLAC 파일은 이진 파일이므로 json 형식으로 보내기 위해 base64 인코딩을 해야 한다. 다음 명령을 입력하여 base64 음성 데이터를 json 파일에 추가하고 JSON 형식에 맞게 음성 데이터스트림이 content 항목에 들어가도록 마지막 3줄을 편집한다.
$ base64 hello.flac >> hello.json
$ nano hello.json
…
"content":"......"
}
}
마지막으로 다음 명령을 입력하면 아래와 같이 음성 인식 결과를 JSON 형식으로 보내준다.
$ curl -X POST -H "Content-Type: application/json" https://speech.googleapis.com/v1/speech:recognize?key= 키> -d @hello.json
{
"results": [
{
"alternatives": [
{
"transcript": "안녕하세요",
"confidence": 0.96446205
}
]
}
]
}
그런데, 앞서 언급하였듯이 이 방식은 API 키 값이 네트워크에 노출될 수 있으므로 자주 사용하는 데는 바람직하지 못하다. 따라서 이번에는 서비스 계정을 이용한 인증 방식을 살펴보자.
구글 클라우드 콘솔의 프로젝트 창에서 상단 메뉴의 왼쪽 탭에서 I AM 및 관리자 항목을 선택한 후 이동한다. 여기서 서비스 계정이 생성되지 않았으면 생성한다. 사용자 인증 정보에서 서비스 계정 키를 선택한다. 서비스 계정 키 만들기에서 새 서비스 계정 클릭하고 사용자 인증 정보를 넣는다. JSON형식을 선택하고 생성 버튼을 클릭하면 키를 생성하고 키 값을 포함한 credentials-key.json 파일을 저장하라는 창이 나타난다. 이 파일을 홈 디렉토리에 저장해 둔다.
.bashrc 파일을 편집하여 GOOGLE_APPLICATION_CREDENTIALS 환경변수를 키 파일로 설정한다.
$ nano ~/.bashrc
,,,
export GOOGLE_APPLICATION_CREDENTIALS=<서비스 계정 키 파일>
서비스 계정을 인증하기 위해서는 구글 클라우드 SDK를 설치해야 한다. 구글 클라우드 SDK를 설치하는 방법은 아카이브 파일을 한번에 다운로드하거나 인터렉티브하게 패키지를 다운로드하면서 설치하는 등 다양한 방법이 있다. 여기서는 아카이브 파일을 다운로드해 보자. 다음 링크로부터 리눅스 x86용 구글 클라우드 SDK 패키지 파일을 다운로드한다. (설치하는 파일들이 파이썬 스크립트들이므로 x86용 패키지를 라즈베리파이에 설치해도 무방하다)
https://cloud.google.com/sdk/downloads#linux
압축 파일을 푼 후에 디렉토리로 이동하여 설치 명령을 실행한다.
$ tar xvfz google-cloud-sdk-<version>-linux-x86.tar.gz
$ cd google-cloud-sdk
$ ./google-cloud-sdk/install.sh
다음 명령을 입력하여 서비스 계정을 인증한다.
$ gcloud auth activate-service-account --key-file=<서비스 계정 키 파일>
서비스 계정을 이용하여 음성 인식을 테스트하기 위해 접근 토큰을 획득한다.
$ gcloud auth application-default print-access-token
<접근 토큰 값>
다음 명령을 입력하여 음성인식 요청을 보내고 응답을 확인한다.
$ curl -H "Content-Type: application/json" -H "Authorization: Bearer <접근 토큰 값>" https://speech.googleapis.com/v1/speech:recognize -d @hello.json
다음은 파이썬 프로그램으로 테스트해 보자. 먼저 구글 클라우드 스피치 파이썬 모듈을 설치한다.
$ pip install --upgrade google-cloud-speech
테스트 스크립트가 포함된 샘플 소스코드를 다운로드한다.
$ git clone https://github.com/GoogleCloudPlatform/python-docs-samples
$ cd python-docs-samples
$ cd speech/cloud-client
테스트 스크립트 파일을 편집하여 한국어가 인식되도록 수정한다.
$ nano transcribe-streaming_mic.py
…
language_code = 'ko-KR' # a BCP-47 language tag
…
$ python transcribe-streaming_mic.py
주의: 스트리밍 예제를 사용하게 되면 지속적으로 클라우드 API를 요청하게 되므로, 상당히 많은 요금이 과금될 수 있습니다. 반드시 프로그램 종료를 확인하고 가능하면 데시보드 홈페이지에서 하루 또는 시간 할당량을 제한하기 바랍니다.
4) SpeechRecognition 패키지
마지막으로 여러 가지 음성인식 엔진을 지원하는 파이썬 패키지인 SpeechRecognition을 사용해 보자. 이 패키지는 앞서 소개한 포켓스핑크스, 구글 스피치 API는 물론 Wit.ai, MS Bing 스피치 API, Houndify API, IBM STT 과 같은 음성 인식 엔진을 사용할 수 있도록 해 준다.
이 패키지를 사용하여 프로그래밍하려면 먼저 사용하려는 음성인식엔진과 관련된 패키지들을 설치해야 한다. 예를 들면 구글 스피치 API를 사용혀려면 pyaudio, google-api-python-client, flac 패키지를 설치해야 한다. 다음 명령을 입력하여 의존 패키지를 설치한다.
$ sudo apt-get install portaudio19-dev python-all-dev python3-all-dev
$ sudo pip install pyaudio # or sudo pip3 install pyaudio
$ sudo pip install google-api-python-client oauth2client
$ sudo apt-get install flac
다음 명령을 입력하여 SpeechRecognition 패키지를 설치한다. 설치하는 도중에 MemoryError 오류가 나타나면 pip 명령에 --no-cache-dir 옵션을 추가한다.
$ sudo pip install SpeechRecognition
이제 다음과 같은 테스트 스크립트를 작성한다.
$ nano speechtest.py
#-*- coding: utf-8 -*-
import sys
#reload(sys)
#sys.setdefaultencoding('utf-8')
import speech_recognition as sr
r = sr.Recognizer()
with sr.Microphone(device_index=2, sample_rate=44100) as source:
#with sr.Microphone(device_index=2) as source:
print("Say something")
r.adjust_for_ambient_noise(source)
audio = r.listen(source)
try:
print("You said: " + r.recognize_google(audio, language = "ko-KR"))
#print("You said: " + r.recognize_google_cloud(audio, language = "ko-KR"))
#print("You said: " + r.recognize_google_cloud(audio))
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
$ python speechtest.py
음성 합성(Speech Synthesis)이란 컴퓨터를 사용하여 텍스트를 음성으로 변환하는 기술을 말하며 다른 말로는 TTS(Text To Speech)라고 한다. 음성 합성 시스템의 구조는 다음과 같다. 텍스트 분석 단계에서는 텍스트의 구조와 언어학적인 분석을 통해 텍스트를 단어들로 분리한다. 이어서 언어 분석 단계에서는 음운분석을 통해 개별적인 음소 단위로 변환하고 운율(prosody) 모델을 통해 말의 운율, 강세, 어조 등에 맞게 실제 음성으로 변환한다. 마지막으로 짧은 음성들을 합성하여 최종 음성 신호를 만들어내고 이를 스피커로 내보낸다.
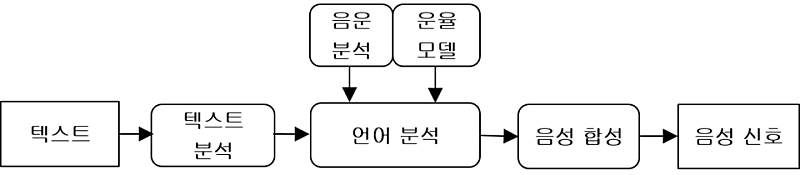
<음성 합성 시스템>
대표적인 TTS 엔진으로는 eSpeak, Festival, Flite, SVoX Pico, Ivona, Google TTS(클라우드) 등이 있다.
다음은 eSpeak, Festival, 구글 TTS를 사용해 보자. 먼저 eSpeak TTS 엔진을 설치하려면 다음 명령을 입력한다.
$ sudo apt-get install espeak
espeak를 사용할 수 있는 파이썬 모듈을 설치한다.
$ sudo pip install pyttsx
다음과 같은 간단한 테스트 프로그램을 작성한다.
$ nano pyttsxtest.py
import pyttsx
engine = pyttsx.init()
engine.say("Sally sells seashells by the seashure.")
engine.say("The quick brown fox jumped over the lazy dog.")
engine.runAndWait()
스크립트를 실행하고 스피커로 합성어로 된 음성을 들어본다.
$ python pyttsxtest.py
다음은 Festival TTS 엔진을 설치해 보자. 다음 명령을 입력하여 Festival 엔진을 설치한다.
$ sudo apt-get install festival festvox-don festival-dev
다음은 파이썬 모듈을 설치한다.
$ sudo pip install pyfestival
다음과 같은 간단한 테스트 프로그램을 작성한다.
$ nano festivaltest.py
#-*- coding: utf-8 -*-
import festival
festival.sayText("Sally sells seashells by the seashure.")
festival.sayText("The quick brown fox jumped over the lazy dog.")
festival.sayText("annyonghaseyo.")
스크립트를 실행하고 스피커로 합성어로 된 음성을 들어본다.
$ python festivaltest.py
마지막으로 Google TTS 엔진을 테스트해 보자. 다음 명령을 입력하여 의존 패키지와 구글 TTS 엔진을 설치한다.
$ sudo apt-get install python-pymad
$ sudo easy_install --upgrade pip
$ sudo pip install --upgrade requests
$ sudo pip install --upgrade gTTS
다음과 같은 테스트 프로그램을 작성한다. 여기서 구글 TTS 는 구글 서버로부터 입력 문장에 대한 mp3 음성 파일을 받아오는 클라우드 방식이므로, 음성을 출력하려면 mpg123과 같은 외부 mp3 재생 프로그램이나 pygame과 같은 미디어 출력 모듈이 필요하다.
$ nano gttstest.py
#-*- coding: utf-8 -*-
from gtts import gTTS
import os, time
from pygame import mixer
tts = gTTS(text='안녕하세요', lang='ko')
tts.save('hello.mp3')
mixer.init()
mixer.music.load('hello.mp3')
mixer.music.play()
while mixer.music.get_busy():
time.sleep(1)
#os.system("mpg123 hello.mp3"
프로그램을 실행하고 음성이 재생되는지 확인한다.
$ python gttstest.py
가상 비서(Virtual Assistant)는 개인을 위해 특정한 일이나 서비스를 해 주는 소프트웨어 에이전트를 말하며, 챗봇(chatbot)이라고 부르기도 한다. 가상 비서는 사용자의 음성이나 텍스트를 실행 명령으로 바꾸기 위해 자연어(Natural Language) 처리가 필요한데, 주로 머신 러닝을 포함한 인공 지능 기술을 사용하여 텍스트를 학습한다.
대표적인 가상 비서로는 아마존 알렉사(Alexa), 구글 어시스턴트(Assistant), 마이크로소프트 코나타(Cortana), 애플 시리(Siri) 등이 있다. 여기서는 구글 어시스턴트와 아마존 알렉사를 사용해 보자.
1) 구글 어시스턴트
구글 어시스턴트 SDK는 2가지 방식을 사용하는데, 하나는 구글 어시스턴트 라이브러리이며 다른 하나는 구글 어시스턴트 서비스이다. 구글 어시스턴트 라이브러리는 파이썬으로 구현되어 있으며, 라즈베리파이와 X86 64비트 CPU를 지원한다. 이 방식은 직접 “OK Google”과 같은 핫워드(hotword)를 감지하여 구동시킬 수 있지만 아직 영어만 지원한다. 반면에 구글 어시스턴트 서비스는 파이썬 뿐만 아니라 gRPC(구글에서 만든 통신 라이브러리)를 지원하는 Node.js, Go, C++와 같은 컴퓨터 언어로 개발할 수 있으며, 영어 뿐만 아니라 한국어 등도 지원한다. 둘의 차이점은 다음 표와 같다.
| 라이브러리 | 서비스 | |
| 지원 CPU | linux-armv7l 및 linux-x86_64 | 모든 gRPC 플랫폼 |
| 지원 언어 | 파이썬 | 모든 gRPC 언어 |
| 핸즈프리 활성화(Ok Google) | 예 | 아니오 |
| 오디오 캡쳐 및 재생 | 빌트인 | 참조 코드 제공 |
| 대화 상태 관리 | 빌트인 | 참조 코드 제공 |
| 타이머 및 알람 | 예 | 아니오 |
| 팟캐스트 및 뉴스 재생 | 예 | 아니오 |
| 음성 메시지 방송 | 예 | 아니오 |
| 시각적 응답 출력(HTML5) | 아니오 | 예 |
구글 어시스턴트 SDK를 설치하는 방법은 다음 링크를 참고한다.
구체적인 과정은 다음과 같다. 먼저 구글 클라우드에 로그인 한 후 액션 콘솔 (https://console.actions.google.com/)로 가서 Add/import project 을 선택하고 프로젝트 이름을 입력하고 CREATE PROJECT를 클릭한 후 화면 제일 아래 부분에서 Device Registration 항목을 클릭하여 새로운 프로젝트를 생성한다.
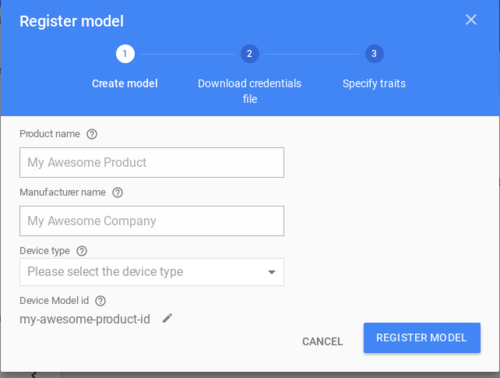
다음은 다시 액션 콘솔 화면으로 이동한 후 해당하는 프로젝트를 선택한다. 왼쪽 메뉴의 제일 아래 Device Registration 항목을 선택하고 REGISTER MODEL 버튼을 클릭한다. 프로젝트 이름, 제조사 이름, 장치 타입을 적절하게 입력한 후 REGISTER MODEL 버튼을 클릭한다.
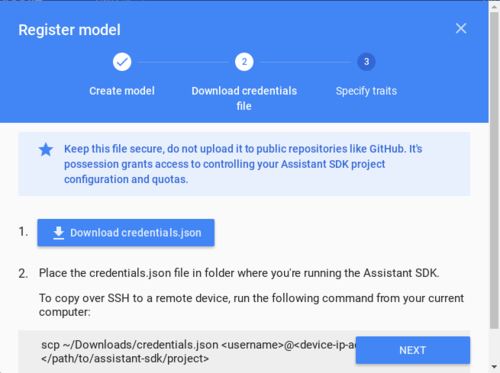
다음 창에서는 인증을 위한 json 인증 파일(credentials.json)을 다운로드한다. 그리고 추가로 지원하는 특성(trait)을 선택하지 않거나 적절하게 선택한 후 장치 모델 등록을 완료한다.
다음은 구글 어시스턴트 라이브러리를 설치해야 한다. 먼저 pip 등의 패키지를 최신 버전으로 갱신한다.
$ sudo apt-get install python3-dev
$ sudo pip3 install --upgrade pip setuptools wheel
$ sudo apt-get install portaudio19-dev libffi-dev libssl-dev libmpg123-dev
다음은 구글 어시스턴트 라이브러리 파이썬 모듈을 설치한다.
$ sudo pip3 install --upgrade google-assistant-library
이제 구글 어시스턴트 SDK 파이썬 모듈을 설치한다.
$ sudo pip3 install --upgrade google-assistant-sdk[samples]
이제 다음 명령을 실행하여 구글 oauthlib 툴을 설치하고 구글 어시스턴트 API를 인증한다.
$ sudo pip3 install --upgrade google-auth-oauthlib[tool]
$ google-oauthlib-tool --client-secrets <credentials.json 인증 파일> --scope https://www.googleapis.com/auth/assistant-sdk-prototype --save --headless
Please visit this URL to authorize this application: <인증 URL>...
Enter the authorization code:
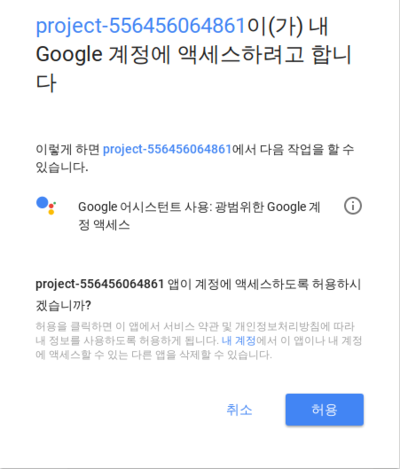
여기서 웹 브라우저를 실행하여 <인증 URL>을 복사하여 붙여넣기로 접속한다. 다음과 같은 메시지가 포함된 창이 나타나면 “허용” 버튼을 클릭한다.
$ google-oauthlib-tool --client-secrets <credentials.json 인증 파일> --scope https://www.googleapis.com/auth/assistant-sdk-prototype --save --headless
Please visit this URL to authorize this application:...
Enter the authorization code: 4/…
Credentials saved: /home/pi/.config/google-oauthlib-tool/credentials.json
저장된 credentials.json 파일은 나중에 다른 컴퓨터에서도 재활용할 수 있다.
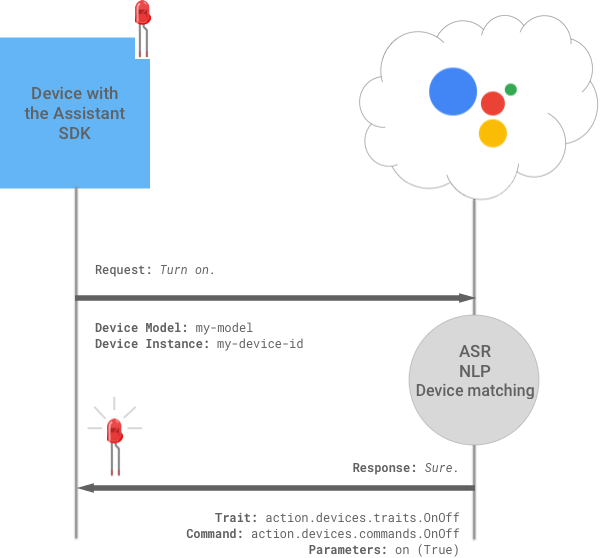
다음은 데모 프로그램을 실행하고 “OK Google, how is the weather in seoul?”과 같은 문자을 인식하고 응답하는지 확인한다.
$ googlesamples-assistant-hotword --project_id <프로젝트ID:예)my-project> --device_model_id <모델ID:예)led-model>
device_model_id: led-model
device_id: 1C3E1558B0023E49F71CA0D241DA03CF # Device instance ID
Registering...Done.
ON_MUTED_CHANGED:
{'is_muted': False}
ON_START_FINISHED
ON_CONVERSATION_TURN_STARTED
ON_CONVERSATION_TURN_FINISHED:
{'with_follow_on_turn': False}
ON_CONVERSATION_TURN_STARTED
ON_END_OF_UTTERANCE
ON_RECOGNIZING_SPEECH_FINISHED:
{'text': 'how is the weather in Busan'}
ON_RESPONDING_STARTED:
{'is_error_response': False}
ON_RESPONDING_FINISHED
ON_CONVERSATION_TURN_FINISHED:
{'with_follow_on_turn': False}
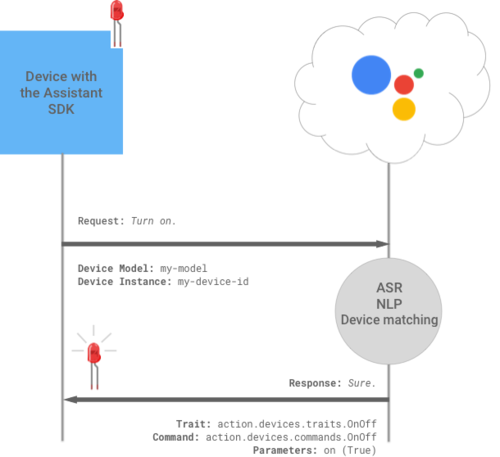
출처: https://developers.google.com/assistant/sdk/images/device-actions.png
이제 음성으로 LED를 제어해 보자. LED를 제어하기 위해 구성한 회로는 다음과 같다.
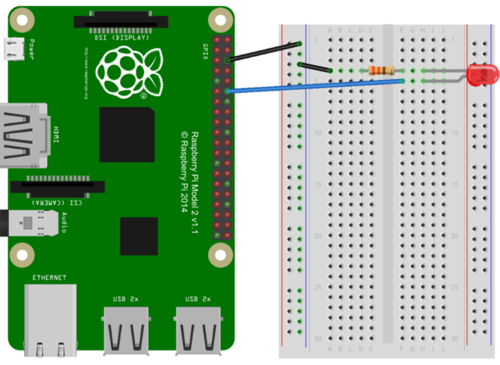
다음은 LED 점멸에 대한 특성(trait)을 추가한다. 액션 콘솔 화면으로 이동한 후 Device Registration 항목을 선택한다. 수정할 모델을 선택한 후에 오른쪽 연필 아이콘을 클릭한다. 다음 화면에서 On/Off 체크박스를 선택한 후에 SAVE 버튼을 클릭하고 다시 SAVE를 클릭한다.
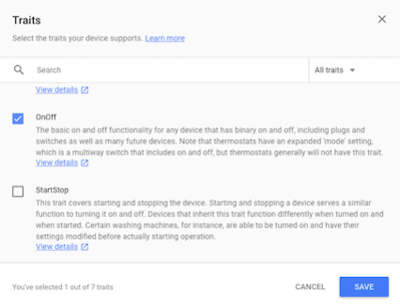
이제 샘플 프로그램을 실행하여 “OK Google, Turn On”을 말해본다. 다음과 같은 응답을 확인한다.
$ googlesamples-assistant-hotword --device_model_id <모델ID>
…
ON_RECOGNIZING_SPEECH_FINISHED:
{'text': 'turn on'}
ON_DEVICE_ACTION:
{'inputs': [{'payload': {'commands': [{'execution': [{'command': 'action.devices.commands.OnOff',
'params': {'on': True}}], 'devices': [{'id': 'E56D39D894C2704108758EA748C71255'}]}]},
'intent': 'action.devices.EXECUTE'}], 'requestId': '4785538375947649081'}
Do command action.devices.commands.OnOff with params {'on': True}
실제로 LED를 점멸하려면 샘플 프로그램 소스코드를 수정해야 한다. 다음 명령을 실행하여 샘플 프로그램을 다운로드하고 해당하는 디렉토리로 이동한다.
$ git clone https://github.com/googlesamples/assistant-sdk-python
$ cd assistant-sdk-python/google-assistant-sdk/googlesamples/assistant/library
이제 hotword.py 소스파일을 열어 다음과 같이 수정한다.
$ nano hotword.py
...
import RPi.GPIO as GPIO
...
with Assistant(credentials, device_model_id) as assistant:
events = assistant.start()
device_id = assistant.device_id
print('device_model_id:', device_model_id)
print('device_id:', device_id + '\n')
GPIO.setmode(GPIO.BCM)
GPIO.setup(18, GPIO.OUT, initial=GPIO.LOW)
...
def process_event(event):
...
print('Do command', command, 'with params', str(params))
...
if command == "action.devices.commands.OnOff":
if params['on']:
print('Turning the LED on.')
GPIO.output(18, 1)
else:
print('Turning the LED off.')
GPIO.output(18, 0)
…
이제 샘플 프로그램을 재실행하고 “OK Google, Turn On”을 하면 LED가 켜지는지 확인한다.
$ python3 hotword.py --device_model_id <모델ID>
그런데 영어 대신 한국어로 “불 켜” 라고 말하면 LED가 켜지도록 하고 싶을 것이다. 한국어로 구글 어시스턴트가 동작하려면 라이브러리 대신 gRPC 방식의 구글 어시스턴트 서비스를 사용해야 한다. 먼저 액션 콘솔에서 프로젝트를 선택한 후 언어를 한국어(Korean)으로 수정한다.
다음은 한국어 액션을 등록하고 구동하기 위해 gactions 프로그램 도구를 다운로드해야 한다. 다음 링크로부터 Linux ARM 버전을 다운로드하여 라즈베리파이에 설치한다.
파일의 실행 모드를 설정한다.
$ chmod +x gactions
다음은 기존에 등록된 액션을 확인한다.
$ ./gactions list --project <프로젝트 ID>
…
Visit this URL:
https://.....
여기서 위 URL을 복사하여 웹 브라우저에서 접속한다. 등록 액션을 확인하려면 계정 접근을 허용해야 하므로 브라우저로부터 코드(4/xxx)를 복사하여 붙여넣기한다. 등록된 액션이 없으면 다음과 같이 출력될 것이다.
Enter authorization code:
…
ERROR: Couldn’t fetch versions
ERROR: Requested entity was not found.
2018/…
이제 커스텀 액션 파일을 작성하여 등록해 보자. 다음과 같은 JSON 액션 파일을 작성한다. 여기서, com.acme.actions.led_switch 이라는 한국어 액션을 정의하고 내부에 질의를 나타내는 com.acme.intents.led_switch라는 인텐트와 응답을 나타내는 fulfillment 가 포함되어 있다는 것을 알 수 있다. 또한 인텐트에는 “켜”와 “꺼”라는 값을 가지는 매개변수 myled_ko 와 trigger 질의문이 정의되어 있으며, fulfillment에는 응답문과 com.acme.commands.led_switch 라는 명령이 정의되어 myled_ko를 전달한다.
$ nano ledaction.ko.json
{
"manifest": {
"displayName": "LED Switch",
"invocationName": "LED Switch",
"category": "PRODUCTIVITY"
},
"locale": "ko",
"actions": [
{
"name": "com.acme.actions.led_switch",
"availability": {
"deviceClasses": [
{
"assistantSdkDevice": {}
}
]
},
"intent": {
"name": "com.acme.intents.led_switch",
"parameters": [
{
"name": "myled_ko",
"type": "LEDState"
}
],
"trigger": {
"queryPatterns": [
"불 $LEDState:myled_ko 줄래"
]
}
},
"fulfillment": {
"staticFulfillment": {
"templatedResponse": {
"items": [
{
"simpleResponse": {
"textToSpeech": "네 불을 $myled_ko.raw 겠습니다."
}
},
{
"deviceExecution": {
"command": "com.acme.commands.led_switch",
"params": {
"switchKey": "$myled_ko"
}
}
}
]
}
}
}
}
],
"types": [
{
"name": "$LEDState",
"entities": [
{
"key": "ON",
"synonyms": [
"켜"
]
},
{
"key": "OFF",
"synonyms": [
"꺼",
]
}
]
}
]
}
이제 작성한 액션을 프로젝트에 등록해 보자.
$ ./gactions update --action_package ledaction.ko.json --project <프로젝트 ID>
Your app for the Assistant for project <프로젝트 ID> was successfully updated…
액션이 성공적으로 등록되면 다음 명령을 입력하여 액션을 실행할 준비한다.
$ ./gactions test --action_package ledaction.ko.json --project <프로젝트 ID>
…
Pushing the app for Assistant for testing…
Your app for the Assistant for project <프로젝트 ID> is now ready for testing…
다음은 샘플 프로그램이 포함된 SDK 디렉토리로 이동한다. 여기서 어시스턴트 라이브러리를 사용하는 hotword 대신에 어시스턴트 서비스를 사용하는 pushtotalk 프로그램을 사용해야 한다.
$ cd assistant-sdk-python/google-assistant-sdk/googlesamples/assistant/grpc
이제 pushtotalk.py 소스파일을 열어 다음과 같이 수정한다.
$ nano pushtotalk.py
...
import RPi.GPIO as GPIO
...
class SampleAssistant(object):
…
def __init__(self, language_code, device_model_id, device_id,
…
GPIO.setmode(GPIO.BCM)
GPIO.setup(18, GPIO.OUT, initial=GPIO.LOW)
...
def main(api_endpoint, credentials, project_id,
...
@device_handler.command('com.acme.commands.led_switch')
def ledswitch(switchKey):
logging.info("Switch LED "+switchKey)
print("Switch LED "+switchKey)
if switchKey == "ON":
print('Turning the LED off.')
GPIO.output(18, 1)
elif switchKey == "OFF":
print('Turning the LED off.')
GPIO.output(18, 0)
time.sleep(1)
…
이제 샘플 프로그램을 실행하고 “불 켜 줄래” 또는 “불 꺼 줄래” 하면 LED 점멸하는지 확인한다. 여기서 한국어를 위해 --lang 인자를 사용하였다.
$ python3 pushtotalk.py --device_model_id <모델ID> --lang ko-KR
좀 더 다양하고 복잡한 액션을 사용하고 싶으면 dialogflow 와 같은 플랫폼을 사용하는 것이 좋을 것이다.
2) 아마존 알렉사:
알렉사(Alexa)는 아마존에서 만든 가상비서 서비스이다.
아마존 알렉사를 라즈베리파이에 설치하는 방법은 비교적 간단하며 다음 링크에 잘 설명되어 있다.
먼저 아마존 개발자 싸이트(http://developer.amazon.com) 에 접속한다. 계정을 만들지 않았으면 만들어야 한다. 다음은 상단의 탭에서 Alexa를 선택하고 Voice Service를 선택한 후에 새로운 장치를 등록하면 장치 ID(ProductID), 클라이언트 ID(ClientID) 및 비밀번호(ClientSecret)에 대한 정보를 획득할 수 있다.
다음 명령을 실행하여 알렉사 샘플 프로그램을 다운로드한다.
설치 스크립트 파일을 열어 앞서 획득한 ProductID, ClientID, ClientSecret에 대한 부분을 수정한다.
$ cd alexa-avs-sample-app
$ nano automated_install.sh
이제 설치 스크립트를 실행한다. 알렉사 프로그램을 설치하는 도중에 몇 가지 물음에 적절히 대답하고 나면 설치가 완료된다.
$ . automated_install.sh
설치가 완료되면 프로그램을 실행시켜 보자. 모두 3개의 터미널을 실행하여 각각 별도의 프로그램을 실행시켜야 한다.
첫 번째 터미널에서는 샘플 프로그램이 아마존 AVS에 인증하도록 해 주는 웹 서버를 실행한다. 다음 명령을 실행하면 5050번 포트를 열고 Node.js 웹 서버를 실행할 것이다.
$ cd ~/Desktop/alexa-avs-sample-app/samples
$ cd companionService && npm start
두 번째 터미널에서는 다음 명령을 통해 샘플 프로그램을 실행하며, 이 프로그램은 AVS와 통신한다.
$ cd ~/Desktop/alexa-avs-sample-app/samples
$ cd javaclient && mvn exec:exec
그런데, 여기서 프로그램을 실행하면 다음 메시지가 포함된 팝업창이 나타날 것이다. “Yes”를 클릭하면 웹 브라우저가 자동으로 실행된다.
Please register your device by visiting the following URL in a web browser and following the instructions: https://localhost:5050/provision/d340f629bd685deeff28a917. Would you like to open the URL automatically in your default browser?
브라우저에서 경고 메시지가 나타나면 창 아래쪽의 Advanced -> Proceed to localhost(unsafe) 버턴을 클릭한다.
이제 아마존 웹 페이지로 로그인한 후에 장치 인증 페이지가 나타나면 장치가 보안 프로파일 접근을 허용하기 위해 OK 버튼을 클릭하면 된다.
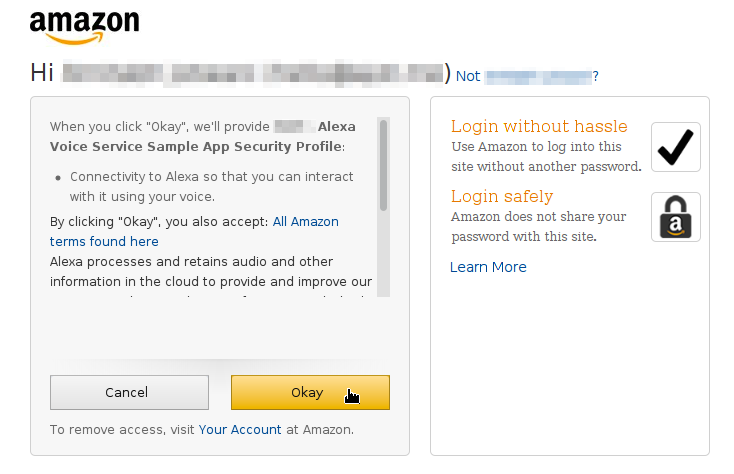
https://github.com/alexa/alexa-avs-sample-app/wiki/assets/avs-device-permission.png
다음과 같은 주소 창으로 재지정되며 “device tokens ready”라는 메시지가 나타날 것이다.
https://github.com/alexa/alexa-avs-sample-app/wiki/assets/avs-device-tokens-ready.png
자바 프로그램으로 돌아가서 OK 버튼을 클릭하면 알렉사 요청을 처리할 준비가 된 것이다.

https://github.com/alexa/alexa-avs-sample-app/wiki/assets/avs-click-ok.png
세 번째 터미널에서는 가상비서의 이름(“알렉사”)에 반응하는 단어 엔진 프로그램을 실행한다. (이 터미널은 반드시 필요하지는 않다) 현재 Sensory와 KITT.AI 엔진을 지원한다.
Sensory 엔진은 다음과 같이 실행한다. 그리고 나서 마이크에 “알렉사”라고 말해본다.
$ cd ~/Desktop/alexa-avs-sample-app/samples
$ cd wakeWordAgent/src && ./wakeWordAgent -e sensory
Kitt.AI 엔진은 다음과 같이 실행한다.
$ cd ~/Desktop/alexa-avs-sample-app/samples
$ cd wakeWordAgent/src && ./wakeWordAgent -e kitt_ai
그런데 공식적인 지원 프로그램 말고도 라즈베리파이와 같은 SBC에서 알렉사를 쉽게 사용할 수 있도록 한 알렉사파이(https://github.com/alexa-pi/AlexaPi)라는 프로젝트가 있다. 이 프로젝트에서는 라즈베리파이를 비롯한 다양한 SBC에서 사용 가능하도록 구성되어 있으며 음성 입력을 위한 트리거링(triggering) 방식으로는 Pocketsphinx를 사용한 단어 인식 방식과 GPIO에 연결한 버튼 방식을 지원한다.
프로그램을 설치하는 방법은 다음과 같다. 다음 명령을 입력하여 소스코드를 다운로드하고 의존 패키지들을 설치한다.
$ git clone https://github.com/alexa-pi/AlexaPi
$ sudo ./AlexaPi/src/scripts/setup.sh
설치하는 도중에 부팅 시 자동으로 실행하려면 /opt 디렉토리에 소스코드를 설치하라고 하는데, 여기서는 테스트만 수행하기 때문에 ‘n’을 입력한다. OS를 ‘debian”으로 입력하고 장치를 ‘raspberrypi’로 입력하고 Airplay는 설치하지 않도록 ‘n’을 선택한다. 계속 진행하여 알렉사를 위한 ProductID, Security Prifile Description, Security Profile ID, Security Client ID, Security Client Secret 을 아마존 개발자 싸이트의 콘솔 페이지를 참고하여 입력하면 auth_web.py 스크립트가 실행되는데 여기서 아마존 서버에 접속하여 refresh token을 받아와서 입력하면 설치가 완료된다.
설치 정보는 config.yaml 파일에 저장되어 스크립트 실행 시에 참고하게 된다. 이 파일 내의 설정 값들은 필요할 때 바꿀 수도 있다. 예를 들면 알렉사 관련 설정값들은 다음과 같이 확인할 수 있다.
$ cd AlexaPi/src
$ nano config.yaml
…
alexa:
Client_ID: <Client ID>
Client_Secret: <Client Secret>
Device_Type_ID: <Device Type ID>
Security_Profile_Description: <Security Profile Description>
Security_Profile_ID: <Security Profile ID>
refresh_token: <Refresh Token>
...
버튼을 통해 트리거링을 하려면 GPIO 18번 포트(12번 핀)에 버튼을 풀업으로 연결하고, GPIO 24, 25번 포트(18, 22번 핀)에 각각 LED를 연결하면 된다. 이제 스크립트를 실행하고 “Alexa”라고 말하면 “Yes”라고 대답할 것이다. 그러면 “What time is it now?” 와 같은 질문을 하고 조금 기다리면 응답하게 된다. 버튼으로 트리거링하려면 버튼을 누른 상태에서 GPIO 24번 LED가 켜지면 말하고 버튼을 떼면 25번 LED가 켜지면서 음성 요청을 아마존 서버에 보내 처리한 뒤 응답하게 된다.
$ python main.py
그런데 앞서 소개한 가상비서들은 질문에 대해 말로 응답은 잘 하지만 전등을 켜거나 음악을 틀거나 하지는 못한다. 이렇게 하려면 특정한 장치나 유료 서비스를 사용해야 할 것이다. 여기서는 그렇게 하지 않고 특정한 음성 요청에 대해 원하는 대로 응답하는 자신만의 가상비서 프로그램을 직접 만들어 보자.
가상비서 프로그램을 제작하는 데 필요한 소프트웨어 모듈로는 음성 입력과 출력을 변환할 수 있는 STT, TTS 엔진은 물론 사용자의 요청 문장에 자동으로 응답하는 챗봇 프로그램이 필요하다. 추가로 한국어를 사용하는 경우에 이를 처리할 한국어 자연어 처리 모듈과 각종 프로그램을 실행하는 소프트웨어 모듈이 필요할 것이다. 여기서는 구글 STT, TTS 엔진과 AIML이라는 규칙 기반 챗봇 처리 모듈과 KoNLPy 한국어 자연어 처리 모듈을 활용할 것이다.
1) aiml (AI Markup Language)
AIML (Artificial Intelligence Markup Language)는 ALICEbot 자유 소프트웨어 재단에서 개발한 챗봇 및 인공지능 자연어 처리를 위한 XML 마크업 언어이다. 이 방식은 규칙 기반의 인공지능 기법을 사용하므로 머신러닝 기법으로 스스로 유연하게 학습하지는 못하지만 기본적인 개념을 이해하는 데는 나름대로 꽤 쓸만하다. AIML의 기본적인 문법은 간단하며 주요 XML 태그에 대한 설명은 다음과 같다.
<aiml> 태그는 aiml 문서의 시작과 깥을 나타낸다. 이 태그에는 버전(version)과 파일 인코딩 형식(encoding)의 속성을 포함할 수 있다. 예를 들면 다음과 같다.
<aiml version="1.0.1" encoding="UTF-8" >
...
</aiml>
<category> 태그는 aiml 을 사용하는 로봇의 기본 지식 블록을 나타낸다. 각 카테고리에는 다음에 소개하는 <pattern>과 <template>로 구성되며, 각각 사용자 입력과 로봇의 응답을 나타낸다. 예를 들면, Kim 이라는 사용자가 “Hello Pi”라고 부르면 “Hello Kim” 이라고 대답하도록 하려면 다음과 같이 만들면 된다.
<category>
<pattern> HELLO PI </pattern>
<template> Hello Kim </template>
</category>
<pattern> 태그는 사용자 입력을 나타낸다. 패턴 태그는 카테고리 태그의 첫번째 태그이며, 단어를 공백(스페이스, ‘ ‘) 로 구분한다. 패턴에는 여러 단어에 대응하는 ‘*’, ‘_’ 와 같은 와일드카드를 사용할 수 있다.
<template> 태그는 로봇 응답을 나타낸다. 템플릿 태그는 패턴 태그 다음에 나타나도록 한다. 이 태그는 해당하는 패턴에 대한 응답을 기술하거나 저장하는 것은 물론 다른 프로그램을 실행하거나 조건에 따른 응답을 할 수도 있다. 예를 들면, 사용자가 “I am *” 라고 하면 로봇이 “Hi *”라고 하는 예제는 다음과 같다.
<category>
<pattern> I AM * </pattern>
<template> Hi * </template>
</category>
다음 태그들은 기타 유용한 용도로 사용되는 태그들이다. <star> 태그는 사용자의 입력에 사용된 와일드카드 항목을 가져오는 태그이다. 다음과 같은 예를 살펴보자. 사용자 입력 패턴이 “ * LIKE * ” 이고 사용자가 “He like apple”이라고 말한다면 각각 첫째 및 둘째 와일드카드 (*)는 각각 “He”와 “apple”에 대응된다. 다음과 같은 구문을 작성하면 사용자 입력에 대하여 로봇은 “Why he like apple?”이라고 대답할 것이다.
<category>
<pattern> * LIKE *. </pattern>
<template> Why <star index="1"/> like <star index="2"/>? </template>
</category>
<srai> 태그는 여러 패턴을 단일 템플릿 태그와 대응하도록 한다. 예를 들면 다음과 같이 여러 가지 인사에 대해서 로봇이 모두 같은 응답을 하도록 할 수 있다.
<category>
<pattern>HELLO</pattern> <template>Hi there!</template>
</category>
<category>
<pattern>HI</pattern> <template><srai>HELLO</srai></template>
</category>
<category>
<pattern>How Are You? </pattern> <template><srai>HELLO</srai></template>
</category>
<set>, <get> 태그는 내부적으로 변수를 정의하고 값을 설정하거나 획득하는 데 사용한다.
<category>
<pattern> I AM * </pattern>
<template> Hi <set name="username"><star />!</set> </template>
</category>
<category>
<pattern> Goodbye </pattern>
<template> Bye <get name="username" /> </template>
</category>
이 밖에도 <random> 태그를 사용하여 동일한 입력에 대해 매번 다르게 응답하거나 <that>과 <topic> 태그를 통해 이전 대화나 특정한 주제를 파악하여 응답하거나 <condition> 태그로 특정한 조건에 반응하도록 만들 수도 있다. 다음 표는 AIML 주요 태그를 보여준다.
| 항목 | 설명 |
| <aiml> | AIML 파일의 시작과 끝을 나타냄 |
| <category> | 로봇의 기본 지식 블록을 나타냄. 아래 <pattern>과 <template>으로 구성 |
| <pattern> | 사용자 입력을 나타냄 |
| <template> | 로봇의 응답을 나타냄 |
| <star> | 사용자 입력에 사용된 와일드카드 항목을 참조 |
| <srai> | 여러 패턴을 단일 탬플릿 태그로 참조 |
| <random> | 랜덤한 패턴을 나타내므로 동일한 입력에 대해 매번 다르게 응답 가능 |
| <set> <get> | 내부적으로 변수 정의/값 설정(<set>)하거나 획득(<get>)하는 데 사용 |
| <that> | 이전 대화의 응답을 참조할 때 사용 |
| <topic> | 현재 대화의 주제 또는 문맥을 생성할 때 사용 |
| <think> | 응답을 숨기거나 내부적으로 처리하는 내용을 나타냄 |
| <condition> | 조건문을 나타냄 |
| <learn> | AIML 파일을 학습할 때 사용 |
| <system> | 시스템 명령을 실행할 때 사용 |
다음은 파이썬 프로그램으로 AIML 태그들을 테스트해 보자. 먼저 다음 명령을 입력하여 파이썬 AIML 모듈인 pyaiml을 설치한다.
$ sudo pip install aiml
이제 간단한 대화를 할 수 있는 입력과 응답에 대한 태그를 포함하는 다음과 같은 AIML 파일을 작성한다.
$ nano basic_chat.aiml
<aiml version="1.0.1" encoding="UTF-8" >
<category>
<pattern> HELLO PI </pattern>
<template> Hello </template>
</category>
<category>
<pattern> I AM * </pattern>
<template> Hi <set name="username"><star />!</set> </template>
</category>
<category>
<pattern> Goodbye </pattern>
<template> Bye <get name="username" /> </template>
</category>
<category>
<pattern> 안녕 파이 </pattern>
<template> 안녕 </template>
</category>
<category>
<pattern> 난 * 이야 </pattern>
<template> 안녕 <set name="username"><star />!</set> </template>
</category>
<category>
<pattern> 나는 * 입니다 </pattern>
<template> 안녕 <set name="username"><star />!</set> </template>
</category>
<category>
<pattern> 나 는 * 입니다 </pattern>
<template> 안녕 <set name="username"><star />!</set> </template>
</category>
</aiml>
AIML 모듈이 잘 동작하는지 확인하기 위해 파이썬 인터프리터를 실행하고 다음 명령을 입력해 본다.
$ python
>>> import aiml
>>> kernel = aiml.Kernel()
>>> kernel.learn('test.aiml')
Loading test.aiml... done (0.00 seconds)
>>> kernel.respond("Hello Pi")
'Hello'
>>> kernel.respond("I am hong")
'Hi hong!'
>>> kernel.respond(u"안녕 파이")
'안녕'
>>>
AIML 모듈의 사용 방법은 간단하다. aiml 모듈을 임포트한 후에 aiml 모듈의 기본 클래스인 aiml.Kernel 클래스를 활용하여 Kernel 객체를 생성한다. 이어서 커널 객체의 learn 메소드를 사용하여 aiml 스크립트 파일을 학습한다. 학습된 커널 객체는 respond 메소드를 사용하여 사용자 입력을 해석하여 적절한 응답 메시지를 반환하게 된다. 여기서는 한글 및 유니코드(utf-8) 입력과 응답 메시지도 지원한다.
여기서 learn 메소드는 학습할 aiml 또는 xml 파일을 인자로 주는데, 하나의 파일을 학습할 때는 직접 aiml 파일을 지정하면 되지만, 여러 개의 파일을 학습해야 할 때는 앞서 사용한 <pattern>, <template>, <learn> 태그를 활용하도록 xml 파일을 작성하면 된다. 예를 들면 다음과 같은 xml 파일을 작성하고 사용자가 “load aiml b”라고 입력하면 여러 개의 AIML 파일을 학습할 것이다.
$ nano std-startup.xml
<aiml version="1.0.1" encoding="UTF-8">
<!-- std-startup.xml -->
<category>
<pattern>LOAD AIML B</pattern>
<!-- This learn an aiml file -->
<template>
<learn>basic_chat.aiml</learn>
<!-- You can add more aiml files here -->
<!--<learn>more_aiml.aiml</learn>-->
</template>
</category>
</aiml>
이제 다음과 같은 파이썬 스크립트를 작성한다.
$ nano aimltest.py
import aiml
# Create the kernel and learn AIML files
kernel = aiml.Kernel()
kernel.learn("std-startup.xml")
kernel.respond("load aiml b")
# Press CTRL-C to break this loop
while True:
print kernel.respond(raw_input("Input >> "))
여기서 프로그램의 구조는 간단하다. AIML 커널 객체를 생성하고 AIML 파일들을 학습한 후에 무한 루프를 돌며 사용자가 입력한 메시지에 대한 응답을 출력한다. 프로그램을 실행시키고 여러 문장을 입력해 보자.
$ python aimltest.py
Loading std-startup.xml... done (0.09 seconds)
Loading basic_chat.aiml... done (0.01 seconds)
Input >> hello
Hello!
Input >> hello pi
Hello!
Input >> i am hong
Hello hong!
Input >> 안녕 파이
안녕!
Input >> 나는 홍길동입니다
WARNING: No match found for input: 나는 홍길동입니다
Input >> 나는 홍길동 입니다
안녕 홍길동!
대체로 AIML 엔진이 잘 동작하는 것을 확인할 수 있다. 그런데 “나는 홍길동입니다”라는 문장은 인식하지 못한다. 왜냐하면 단어의 어간이 조사와 같은 어미와 결합되므로 문장을 올바르게 처리하기 위해서는 어간을 추출하고 분리할 필요가 있다. 이런 기능을 수행하는 패키지로는 영어의 경우 nltk 파이썬 모듈과 한국어의 경우에는 KoNLPy가 있다.
2) KoNLPy
KoNLPy는 한국어 자연어 처리를 위한 파이썬 모듈이며, 한국어 형태소를 분석하는 엔진과 한국어 자료로 된 말뭉치(corpus)를 포함하고 있다. 현재 한나눔(KAIST), Kkma(서울대), Komoran(샤인웨어), Mecab(교토대및저자), Twitter 등의 다양한 형태소 분석 엔진을 내장하고 있다.(참고: http://konlpy.org)
패키지는 세부적으로 형태소 분석기 엔진을 정의한 Tag 서브패키지, Kolaw(대한민국헌법)와 kobill(법률)을 포함한 여러 말뭉치를 포함하는 Corpus 서브패키지와 기타 data(패키지경로), downloader(konlpy서버데이터접근), jvm(JVM초기화), utils(코드변환,csv파일처리,텍스트출력 등) 모듈로 구성되어 있다. Tag 서브패키지는 Hannanum, Kkma, Komoran, Mecab, Twitter 클래스를 비롯하여 analyze(형태소 후보, Hannanum), morphs(형태소 파싱), nouns(명사 추출), pos(POS 태거) 메소드를 포함하고 있다.
이제 다음 명령을 입력하여 KoNLPy 패키지를 설치해 보자.
$ sudo pip install konlpy
그런데, Mecab 엔진은 별도로 설치해야 한다. 다음 명령을 입력하여 Mecab 관련 패키지들을 설치한다.
$ sudo apt-get install curl
$ bash <(curl -s https://raw.githubusercontent.com/konlpy/konlpy/master/scripts/mecab.sh)
그런데, mecab 한글 사전 및 파이썬 모듈을 설치하는 도중 오류가 날 수 있는데, 이럴 때는 직접 수동으로 다음 명령을 입력하여 패키지들을 재설치할 필요가 있다.
$ sudo ldconfig
$ cd /tmp/mecab-ko-dic-2.0.1-20150920/
#$ sudo sh -c 'echo "dicdir=/usr/local/lib/mecab/dic/mecab-ko-dic" > /usr/local/etc/mecabrc'
$ sudo make install
$ cd /tmp/mecab-python-0.996/
$ sudo python setup.py install
$ sudo python3 setup.py install
$ cd
$ sudo rm -rf /tmp/mecab*
이제 설치가 제대로 되었으면 잘 동작하는지 테스트해 볼 필요가 있다. 다음과 같은 명령을 입력해 본다.
$ python
>>> from konlpy.tag import Hannanum
>>> hannanum = Hannanum()
>>> print(hannanum.analyze(u'롯데마트의 흑마늘 양념 치킨이 논란이 되고 있다.'))
[[[('롯데마트', 'ncn'), ('의', 'jcm')], [('롯데마트의', 'ncn')], [('롯데마트', 'nqq'), ('의', 'jcm')], [('롯데마트의', 'nqq')]], [[('흑마늘', 'ncn')], [('흑마늘', 'nqq')]], [[('양념', 'ncn')]], [[('치킨', 'ncn'), ('이', 'jcc')], [('치킨', 'ncn'), ('이', 'jcs')], [('치킨', 'ncn'), ('이', 'ncn')]], [[('논란', 'ncpa'), ('이', 'jcc')], [('논란', 'ncpa'), ('이', 'jcs')], [('논란', 'ncpa'), ('이', 'ncn')]], [[('되', 'nbu'), ('고', 'jcj')], [('되', 'nbu'), ('이', 'jp'), ('고', 'ecc')], [('되', 'nbu'), ('이', 'jp'), ('고', 'ecs')], [('되', 'nbu'), ('이', 'jp'), ('고', 'ecx')], [('되', 'paa'), ('고', 'ecc')], [('되', 'paa'), ('고', 'ecs')], [('되', 'paa'), ('고', 'ecx')], [('되', 'pvg'), ('고', 'ecc')], [('되', 'pvg'), ('고', 'ecs')], [('되', 'pvg'), ('고', 'ecx')], [('되', 'px'), ('고', 'ecc')], [('되', 'px'), ('고', 'ecs')], [('되', 'px'), ('고', 'ecx')]], [[('있', 'paa'), ('다', 'ef')], [('있', 'px'), ('다', 'ef')]], [[('.', 'sf')], [('.', 'sy')]]]
>>> print(hannanum.morphs(u'롯데마트의 흑마늘 양념 치킨이 논란이 되고 있다.'))
['롯데마트', '의', '흑마늘', '양념', '치킨', '이', '논란', '이', '되', '고', '있', '다', '.']
>>> print(hannanum.nouns(u'다람쥐 헌 쳇바퀴에 타고파'))
['다람쥐', '쳇바퀴', '타고파']
>>> from konlpy.tag import Komoran
>>> komoran = Komoran()
>>> print(komoran.morphs(u'우왕 코모란도 오픈소스가 되었어요'))
['우왕', '코', '모란', '도', '오픈소스', '가', '되', '었', '어요']
>>> print(komoran.nouns(u'오픈소스에 관심 많은 멋진 개발자님들!'))
['오픈소스', '관심', '개발자']
>>> from konlpy.tag import Mecab
>>> mecab = Mecab()
>>> print(mecab.morphs(u'영등포구청역에 있는 맛집 좀 알려주세요.'))
['영등포구', '청역', '에', '있', '는', '맛집', '좀', '알려', '주', '세요', '.']
>>> print(mecab.nouns(u'우리나라에는 무릎 치료를 잘하는 정형외과가 없는가!'))
['우리', '나라', '무릎', '치료', '정형외과']
이제 다음과 같이 한국어 형태소 분석을 통한 AIML 챗봇을 작성해 보자.
$ nano koaimltest.py
import aiml
from konlpy.tag import Mecab
mecab = Mecab()
kernel = aiml.Kernel()
kernel.learn("std-startup.xml")
kernel.respond("load aiml b")
# Press CTRL-C to break this loop
while True:
data = raw_input("Input >> ")
nldata = mecab.morphs(data.decode('utf-8'))
print kernel.respond(" ".join(nldata))
$ python koaimltest.py
...
>> 나는 홍길동입니다
안녕 홍길동!
잘 동작하는 것을 확인할 수 있다. 이번에는 라즈베리파이에 LED를 연결하고 텔레그램을 통해 직접 LED를 켜고 끄는 챗봇을 구현해 보자. 먼저 다음과 같이 AIML 파일에 LED를 켜고 끄는 규칙을 추가한다.
$ nano basic_chat.aiml
…
<category>
<pattern> 불 켜 </pattern>
<template> 불을 꼈습니다<system>python led.py 1</system> </template>
</category>
<category>
<pattern> 불 꺼 </pattern>
<template> 불을 껐습니다<system>python led.py 0</system> </template>
</category>
<category>
<pattern> 오늘 몇 일 이 야 </pattern>
<template> day </template>
</category>
<category>
<pattern> 공부 해 </pattern>
<template> load_aiml </template>
</category>
</aiml>
실제로 LED를 켜고 끄는 파이썬 스크립트를 작성한다.
$ nano led.py
import sys
import RPi.GPIO as GPIO
GPIO.setmode(GPIO.BCM)
GPIO.setwarnings(False)
GPIO.setup(12, GPIO.OUT)
def on():
GPIO.output(12, GPIO.HIGH)
def off():
GPIO.output(12, GPIO.LOW)
if len(sys.argv) >= 2:
print sys.argv[1]
if sys.argv[1] == '1':
on()
elif sys.argv[1] == '0':
off()
elif sys.argv[1] == 'd':
GPIO.cleanup()
다음은 여러 가지 질문에 대해 시스템의 특정한 기능을 수행하는 스크립트를 작성한다. 예를 들면 오늘 날짜를 질문하면 파이썬 datetime 모듈을 통해 올바른 날짜를 대답하도록 한다.
$ nano action.py
#-*- coding: utf-8 -*-
import os
import subprocess
import datetime
def today():
day = datetime.date.today().strftime("%Y년 %m월 %d일")
return " ".join([u"오늘은", day.decode('utf-8'), u"입니다"])
def disk_space():
'''Check available disk space'''
result = subprocess.check_output("df -h .", shell=True)
output = result.split()
formatted_output = {
'total':output[8],
'used':output[9],
'used_percentage':output[11],
'free':output[10]}
return 'Disk space:\nTotal: {total}\nUsed:{used} ({used_percentage})\nFree:{free}'.format(
**formatted_output)
def load_aiml(kernel):
'''reload aiml files'''
kernel.respond('load aiml b')
return 'brain reloaded'
def save(kernel):
'''save brain file'''
kernel.saveBrain("bot_brain.brn")
return 'brain saved'
def perform_action(message, kernel):
'''perform user actions '''
action_index = [c in message for c in actions.keys()].index(True)
try:
response = actions[actions.keys()[action_index]](kernel)
except ValueError:
response = 'Error during executing actions'
return response
actions = {
'disk':disk_space,
'load_aiml':load_aiml,
'space':disk_space,
'day':today,
'save':save}
if __name__ == "__main__":
print today()
마지막으로 텔레그램 메시지에 응답하는 스크립트를 작성한다.
$ nano telegrambot.py
import aiml
from konlpy.tag import Mecab
import telegram
from action import perform_action, actions
mecab = Mecab()
kernel = aiml.Kernel()
kernel.learn("std-startup.xml")
kernel.respond("load aiml b")
token = '<TOKEN>'
bot = telegram.Bot(token=token)
last_update_id = None
# Press CTRL-C to break this loop
while True:
for update in bot.getUpdates(offset=last_update_id, timeout=10):
chat_id = update.message.chat_id
message = update.message.text.encode('utf-8')
if message != None:
nldata = mecab.morphs(message.decode('utf-8'))
resp = kernel.respond(" ".join(nldata))
if any(q in resp for q in actions.keys()):
resp = perform_action(resp, kernel)
if len(resp) != 0:
bot.sendMessage(chat_id=chat_id, text=resp)
last_update_id = update.update_id + 1
텔레그램 봇과의 대화를 통해 원하는 대로 잘 동작하는지 확인한다.
다음은 앞서 구현한 내용을 바탕으로 음성을 인식하고 원하는 대로 응답하도록 동작하는 가상비서 프로그램을 작성해 보자.
$ nano voicebot.py
#-*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import aiml
import os
import time
from gtts import gTTS
from konlpy.tag import Mecab
from action import perform_action, actions
from pygame import mixer
import warnings
import re
from google.cloud import speech
import grpc
import pyaudio
from six.moves import queue
# Audio recording parameters
RATE = 16000
CHUNK = int(RATE / 10) # 100ms
def speak(speech):
tts = gTTS(text=speech, lang='ko')
tts.save('/dev/shm/speech.mp3')
mixer.init()
mixer.music.load('/dev/shm/speech.mp3')
mixer.music.play()
while mixer.music.get_busy():
time.sleep(1)
#os.system('mpg123 /dev/shm/speak.mp3')
class MicAsFile(object):
"""Opens a recording stream as a file-like object."""
def __init__(self, rate, chunk):
self._rate = rate
self._chunk = chunk
# Create a thread-safe buffer of audio data
self._buff = queue.Queue()
self.closed = True
def __enter__(self):
self._audio_interface = pyaudio.PyAudio()
self._audio_stream = self._audio_interface.open(
format=pyaudio.paInt16,
# The API currently only supports 1-channel (mono) audio
# https://goo.gl/z757pE
channels=1, rate=self._rate,
input=True, frames_per_buffer=self._chunk,
# Run the audio stream asynchronously to fill the buffer object.
# This is necessary so that the input device's buffer doesn't
# overflow while the calling thread makes network requests, etc.
stream_callback=self._fill_buffer,
)
self.closed = False
return self
def __exit__(self, type, value, traceback):
self._audio_stream.stop_stream()
self._audio_stream.close()
self.closed = True
# Flush out the read, just in case
self._buff.put(None)
self._audio_interface.terminate()
def _fill_buffer(self, in_data, frame_count, time_info, status_flags):
"""Continuously collect data from the audio stream, into the buffer."""
self._buff.put(in_data)
return None, pyaudio.paContinue
def read(self, chunk_size):
if self.closed:
return
# Use a blocking get() to ensure there's at least one chunk of data.
data = [self._buff.get()]
# Now consume whatever other data's still buffered.
while True:
try:
data.append(self._buff.get(block=False))
except queue.Empty:
break
if self.closed:
return
return b''.join(data)
# [END audio_stream]
def listen_print_loop(results_gen):
"""Iterates through server responses and prints them.
The results_gen passed is a generator that will block until a response
is provided by the server. When the transcription response comes, print it.
response is an interim one, print a line feed at the end of it, to allow
the next result to overwrite it, until the response is a final one. For the
final one, print a newline to preserve the finalized transcription.
"""
num_chars_printed = 0
for result in results_gen:
if not result.alternatives:
continue
# Display the top transcription
transcript = result.transcript
# Display interim results, but with a carriage return at the end of the
# line, so subsequent lines will overwrite them.
#
# If the previous result was longer than this one, we need to print
# some extra spaces to overwrite the previous result
overwrite_chars = ' ' * max(0, num_chars_printed - len(transcript))
if not result.is_final:
sys.stdout.write(transcript + overwrite_chars + '\r')
sys.stdout.flush()
num_chars_printed = len(transcript)
else:
#print(transcript + overwrite_chars)
#print(transcript)
nldata = mecab.morphs(transcript.decode('utf-8'))
speech = kernel.respond(" ".join(nldata))
if any(q in speech for q in actions.keys()):
speech = perform_action(speech, kernel)
print speech
if len(speech) != 0:
speak(speech)
else:
speak("무슨 말인지 모르겠습니다.")
# Exit recognition if any of the transcribed phrases could be
# one of our keywords.
if re.search(r'\b(exit|quit)\b', transcript, re.I):
print('Exiting..')
break
num_chars_printed = 0
def main():
speech_client = speech.Client()
with MicAsFile(RATE, CHUNK) as stream:
audio_sample = speech_client.sample(
stream=stream,
encoding=speech.encoding.Encoding.LINEAR16,
sample_rate_hertz=RATE)
# See http://g.co/cloud/speech/docs/languages
# for a list of supported languages.
language_code = 'ko-KR' # a BCP-47 language tag
results_gen = audio_sample.streaming_recognize(
language_code=language_code, interim_results=True)
#results_gen = audio_sample.recognize(language_code=language_code)
# Now, put the transcription responses to use.
listen_print_loop(results_gen)
if __name__ == '__main__':
mecab = Mecab()
kernel = aiml.Kernel()
if os.path.isfile("bot_brain.brn"):
kernel.bootstrap(brainFile = "bot_brain.brn")
else:
kernel.bootstrap(learnFiles = "std-startup.xml", commands = "load aiml b")
#kernel.saveBrain("bot_brain.brn")
main()
프로그램을 실행하고 여러 가지 말로 다양한 동작을 시켜 본다.
$ python voicebot.py
참고자료
[2] 구글 클라우드 스피치 API 홈페이지 https://cloud.google.com/speech/docs/
[3] 파이썬 Speech Recognition 모듈 홈페이지 https://pypi.python.org/pypi/SpeechRecognition/
[4] eSpeak 홈페이지 http://espeak.sourceforge.net/
[5] Festival 홈페이지 http://www.cstr.ed.ac.uk/projects/festival/
[6] 알렉사 설치 https://github.com/alexa/alexa-avs-sample-app/wiki/Raspberry-Pi
[7] 구글 어시스턴트 설치 https://developers.google.com/assistant/sdk/prototype/getting-started-pi-python/
[8] AIML 홈페이지 http://www.alicebot.org/aiml.html
[0] KoNLPy 홈페이지 http://konlpy.org
'라즈베리파이' 카테고리의 다른 글
| RPI Cloud Cam 따라하기 (0) | 2022.05.18 |
|---|---|
| [Raspberry Pi] 웹캠 연결하기(motion) (0) | 2022.05.18 |
| 라즈베리파이 + MAX7219 아두이노 8X32 도트 매트릭스 모듈 (0) | 2022.05.16 |
| 32x16 RGB LED matrix panel 라즈베리파이에서 사용하기 (0) | 2022.05.16 |
| Getting a ST7735 TFT Display to work with a Raspberry Pi (0) | 2022.05.16 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
댓글